预测模型(predictive models)通常是用来估计一个事件在未来发生的概率——比如明天会不会下雨?哪些用户最有可能退订服务?
其实,预测天气并不是为了改变它,而是为了适应它。但在商业情境中,我们更多的是想要在预测后采取行动,从而改变结果。
所以在这种情况下,我们要的不仅是「预测」,而是「药方」。
当我们知道了采取某个行动会产生怎样的影响后,我们就可以把资源集中到效果最好的地方,而不在效果微乎其微或者是容易产生反作用的地方浪费资源。
这就是增量模型的思维模式。
为了更好地理解增量模型,我们先看看它和传统预测模型之间有什么区别。
预测模型 vs 增量模型
很多时候,预测模型的结果或许能告诉我们:电信公司的哪些用户最可能流失、医院的哪个病人最可能康复、慈善组织中的哪些人最有可能捐赠。但它并不会告诉我们,该如何行动。
预测模型对有些场合已经够用了,比如天气预报。因为我们无法改变天气,我们只能选择做好准备。
但在我们能够作出改变的时候,我们当然想影响结果。比如,电信公司会考虑如何留住那些想退订的用户,给他们免费升级套餐能降低用户流失吗?人力资源分析师会思考搬家费能不能让候选人更有可能接受offer?
其实,增量模型最常见的例子是在营销领域。
它的目标并不是预测客户购买的可能性,而是提高客户购买的可能性。模型会告诉你,与其花钱去试图影响那些已经支持你的人,还不如去影响一个还没有支持你,但「可能被广告说服的人」
增量增的是什么?
增量模型增的到底是什么呢?就是购买行为在有广告时比没有广告时上升了多少(不一定是购买行为,而是任何我们希望用户产生的行为;也不一定是广告,可以是任何实验处理)。这不是能直接观察或测量出来的东西,我们只能在实验中推论出这个因果关系。
在介绍这个模型前,我们先看一个2x2的矩阵,这个矩阵把你所有的用户分成了4个类型:
a. 可以被广告影响的人 Persuadable
b. 忠实的支持者 Sure Thing
c. 请勿打扰者 Do-Not-Disturb
d. 没有希望拉拢的人 Lost Cause
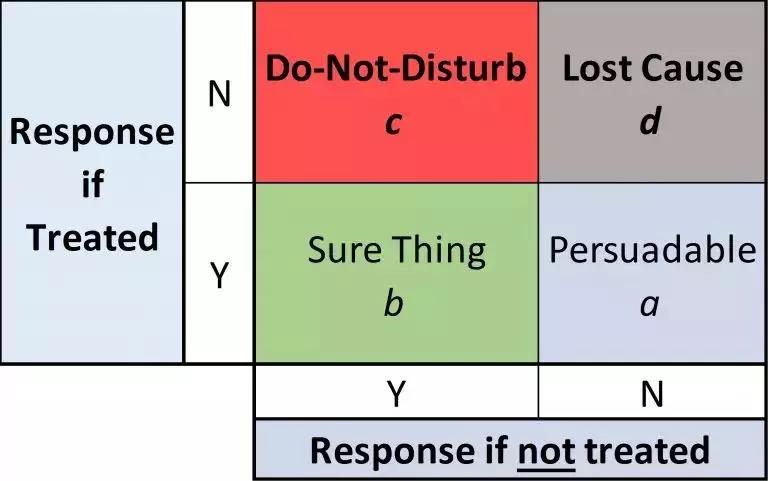
这四种人中我们最应该关心的是a类人——可以被广告影响的人。对于b类和d类人,广告其实是浪费的。对于c类「请勿打扰者」,广告的效果是适得其反的。他们可能本来有可能买你的产品,但广告反而让他们抵触。这些人也被称为「sleeping dog」,因为打扰他们就像唤醒沉睡的狗一样,我们更希望「就让他们去」。
增量模型的目标就是找到可以被广告影响的a类人。然后对这些人进行广告投放。
估计增量
现在我们来用一个案例说明。
假设有一家电信公司想要减少用户流失,他们采取的行动就是给那些可能流失的用户免费升级他们的电信套餐。那怎么样找到「可以被这个优惠政策说服的用户」,并给他们实施这套方案,把他们留住呢?
我们用增量模型来解决这个问题。
首先,我们要做一个实验,这个实验的目的是给增量模型提供必要的数据。我们从电信公司几千万个账户中抽取2000个账户用来做实验。
我们随机选择400个电信账户设为试验组(test group),对于这些人,我们给他们免费升级套餐(所以免费升级套餐就是实验处理)。
我们另外再选1600个账户,不给他们升级套餐,所以他们就是控制组(control group)。
然后我们比较这两组账户在流失率上的差别。
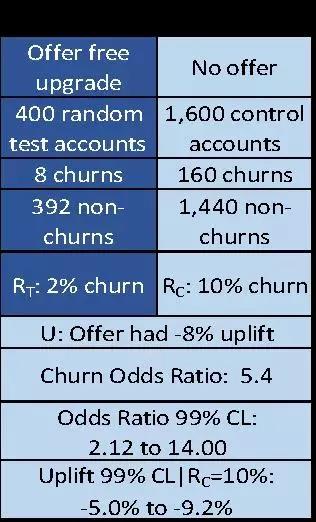
我们发现,测试组的400个账户中有8个用户流失了,流失率2%。控制组的1600个账户中有160人流失了,流失率是10%。所以,测试组和控制组相比,有-8%的增量(这个例子中,用户流失是不好的,所以负值意味着「留存」的增加。)
总体增量 U = 测试组结果RT – 控制组结果RC = 2% – 10% = -8%
千万不要以为到这一步就结束了。好戏还在后头。
实验做完后,就到了增量模型最重要的一个环节——计算出每个用户的实验处理效应(treatment efffect)。也就是说,虽然试验组的流失率总体上比控制组低,但这是总体的结果,每个个人是不一样的,可能试验组里的有些人喜欢「免费升级」并被它说服了,但另一些人对它无动于衷,甚至还有人反而被它激怒。
所以我们可以用用户的特征变量——比如性别、年龄、收入、网购记录等等——来分别预测在有「免费升级」和没有「免费升级」的两种情况下的用户流失率。
模型具体的步骤是这样的:
- 在有实验处理的情境中(也就是「免费升级」),用个人特性变量预测用户流失率
- 在没有实验处理的情境中(也就是没有「免费升级」),用个人特性变量预测用户流失率
- 计算两组流失率的差距(Ui=RTi-RCi)
- 计算差距的置信区间
当有了这些重要的数值之后,我们就可以把所有用户他们每个人的特征值带入,并计算每个个体的置信区间。根据这些置信区间,我们可以把所有个体归类进矩阵里的四种类型:
- 如果置信区间包括零值,则「免费升级」这个措施对这个人来说就是没有显著功效的。那他就要么是忠实的支持者Sure Thing,要么是没有希望拉拢的人Lost Cause,所以你不用浪费精力在他的身上。
- 如果置信区间大于零,那就说明「免费升级」对他是有作用的,那当结果为正时,他就是「可以被说服的人」。
- 当置信区间小于零,那就说明实验处理降低了期望的结果的发生概率,也就是免费升级对他是有反作用的,那这些人就是「请勿打扰者」。
通过这种办法,我们就可以把所有用户分成这四类人啦!然后只要给「可被说服的人」发广告「免费升级」他们的套餐就行啦!
获得营销投资回报
在商业中理解一个行为的投资回报率是非常重要的。增量模型让你可以估算一个处理的回报,只要加总处理对于那些「可被说服的人」的增量(incremental uplift)就行,这就是整体的处理效果(treatment effect)。
Mike Thurber@Marteker技术营销官(marteker)
首席增长官CGO荐读:
更多精彩,关注:增长黑客(GrowthHK.cn)
增长黑客(Growth Hacker)是依靠技术和数据来达成各种营销目标的新型团队角色。从单线思维者时常忽略的角度和高度,梳理整合产品发展的因素,实现低成本甚至零成本带来的有效增长…
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/18297.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫