赵煜杨
百度 | 资深研发工程师
负责手百小程序数据产品的工程架构工作,从0到1主持设计了精细化用户分层系统,实现了百亿级TB量级小程序用户画像、行为数据秒级预估,保障了小程序私域运营的落地。具有超过6年在高可用、大数据方向的工作经验,一直专注在数据工程架构、个性化推荐工程等工作上,对技术团队管理也比较有经验,目前个人专注于大数据、个性化推荐、高可用架构等技术方向。
本文的主题为基于Doris的小程序用户增长实践,将从实际案例出发介绍基于 Doris 用户分层解决方案,重点分享了项目中的难点和架构解决方案,以及怎么使用 Doris做用户分层,如何做到秒级的人数预估和快速产出用户包。主要内容包括:
- 小程序私域精细化运营能力介绍
- 用户分层技术难点
- 用户分层的架构和解决方案
- 未来规划
01小程序私域精细化运营能力介绍
好,现在开始。现在首先介绍一下我们小程序当前的私域精细化运营的能力有哪些。

首先我们为啥要做思域精细化运营呢,这起源于两个痛点:
- 私域用户的价值不突出比如:我有100万个用户,我想给高收入人群去推荐奢侈品的包包,但是我不知道在这100万人里面有多少人是这种高收入人群
- 缺乏主动触达的能力
然后针对这两个问题,我们产品上面提出了一个解决方案 -- 就是分层运营,它主要分为两部分:一个是运营触达,还有一个是精细化的人群。
举个例子:如图示,从上往下看:当运营想搞一个活动时(比如 DataFun Talk 这个活动),可以选择消息、私信、卡券、小程序内这四个通路中的一个进行推送,选完通路之后,就需要选择需要推送的人群,这时候就要用到精细化人群,精细化人群是基于百度大数据平台提供的画像数据、新闻数据生成的,最后根据选择人群、推送通路完成推送。之后我们还会提供触达效果的分析,主要包括下发量、点展、到达之类的,另外针对人群也会提供整个用户群体更细致化的分析。
这套解决方案的收益和价值:
对于开发者来说:
- 合理地利用私域流量提升价值
- 促进用户活跃和转化
对于整个生态来讲:
- 提高了私欲利用率和活跃度
- 激活了开发者主动经营的意愿
- 促进了生态的良性循环
以上讲的是一个产品的方案,接下来跟大家讲一下具体的功能
1. 分层运营-B端视角
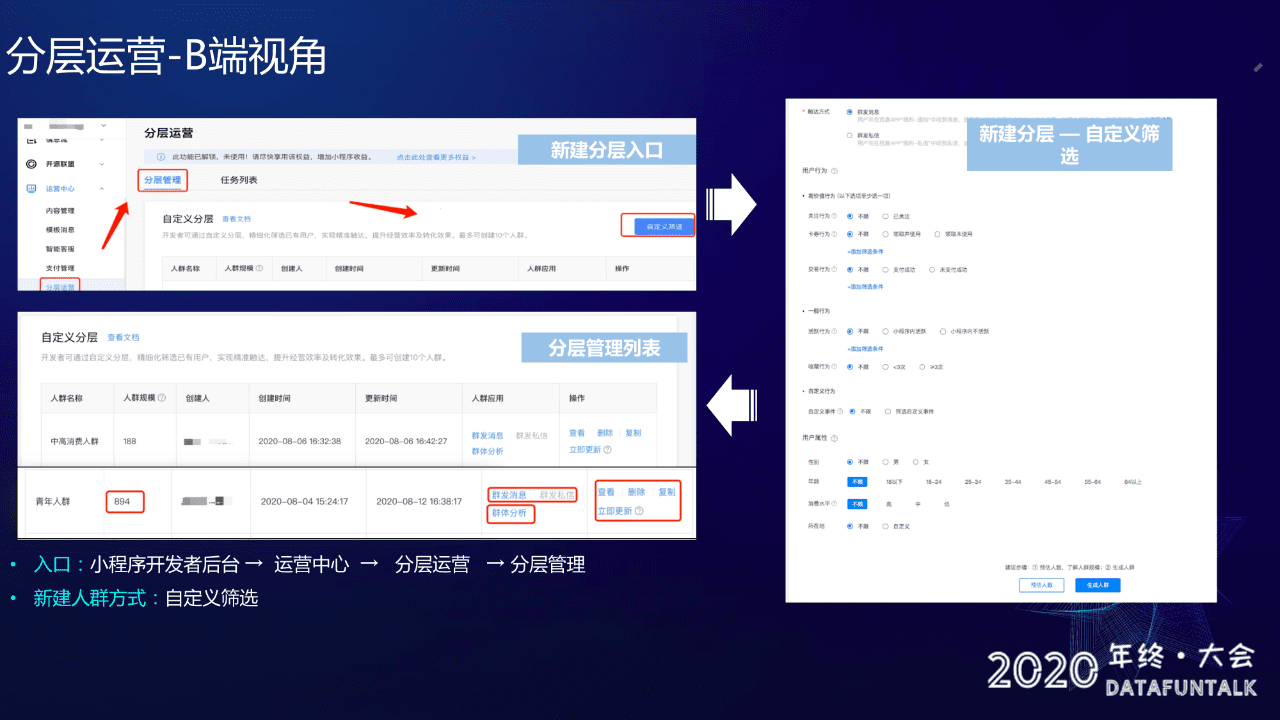
首先介绍下 B 端视角下分层运营平台是如何工作的,比如说我是开发者,我是怎么去做去创建用户分层的。
这里我们提供了自定义配置筛选的功能,可以从用户关注、卡券、交易、活跃行为、性别、年龄等多种维度选择,同时提供了预估人数的功能,可以实时的算出来你当前圈选的用户有多少人,方便评估一下人数是否 OK,如果 OK 的话,就直接生成人群,如果不 OK 的话,就重新选择筛选条件。
完成人群筛选之后,会进入分层管理列表,在列表里面可以根据需要点击对应的推送按钮就可以直接推送,推送方式包括私信、群发。当然了,这里也有群体分析功能。
B 端功能入口:
小程序开发者后台 -> 运营中心 -> 分层运营 -> 分层管理 -> 自定义筛选
2. 分层运营-C端视角
简单展示下 C 端视角下分层运营的一个样式:如图截取的是百度APP 上通知和私信的样式。
02用户分层技术难点
1. 分层运营经典案例
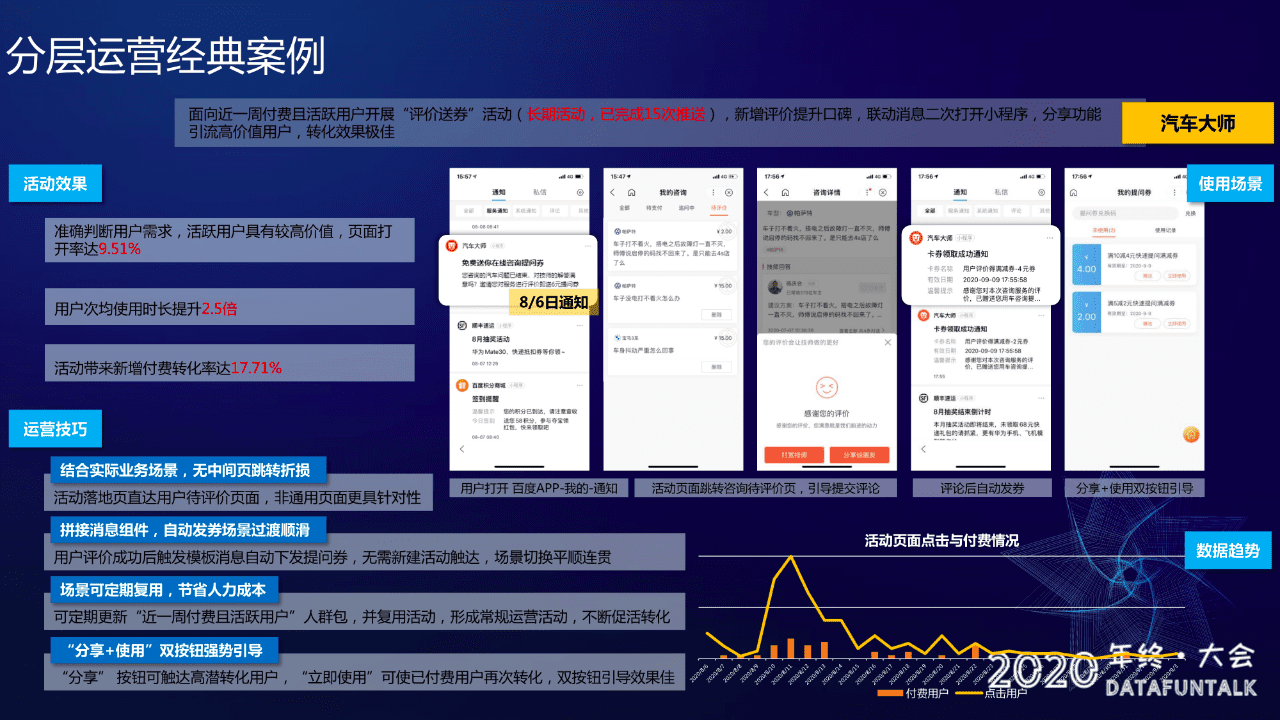
下面给大家介绍分层运营的一个经典的案例 -- 我们跟汽车大师的合作案例:
需求是汽车大师要对近一周付费且活跃的用户进行一个评价送券的活动。图中截图展示了这个活动的交互过程:汽车大师推送一个通知(图中:8/6日通知),然后用户在《 百度APP -> 我的 -> 通知 》里面就可以看到汽车大师的通知消息,点开之后跳转到《咨询待评价页面》,然后写完评价后系统会自动发券并通知给用户;在这个活动中达成的效果如下:
- 准确判断了用户需求,活跃用户价值,页面的打开率达到了 9.51%
- 用户次均使用时长提升 2.5 倍
- 活动带来新增付费转化率达 17.71%
简单介绍下一些这里面的基本运营技巧:
- 结合和实际的业务场景,无中间页跳转的折损
- 拼接消息组件,自动发券场景过度顺转
- 场景可定期复用,节省人力成本。创建完人群之后,可以一直使用,不需要重复创建
- "分享和使用" 双按钮强强势引导
上面的分享主要是让大家了解用户分层运营给开发者带来运营效率以及转化效果的一个提升,从而促进用户增长。这种看起来是特别的香,对不对 ?但是它有没有什么技术难点,答案是当然有,而且还特别大,不过没关系,大家不用担心了,你们认真听完煜杨老师接下来的分享这些难点就会变得很 Easy了,用之前一句特别流行的广告语就是:妈妈再也不用担心我的工作了。
2. 分层运营难点
难点的话,大家可以看下图,可以看到我把难点跟方法论都放到了一起,其实最开始我是想先讲难点,然后后面再讲方法论的,这样的话就可以调一下大家的胃口😁。后来我又一想,大家都是程序员对不对,既如此,程序员何苦为难程序员,还是少一些套路,多一些真诚比较好。所以最后,我就把难点跟方法论都放到一起了,这样可以给大家一个直观的一个认识。
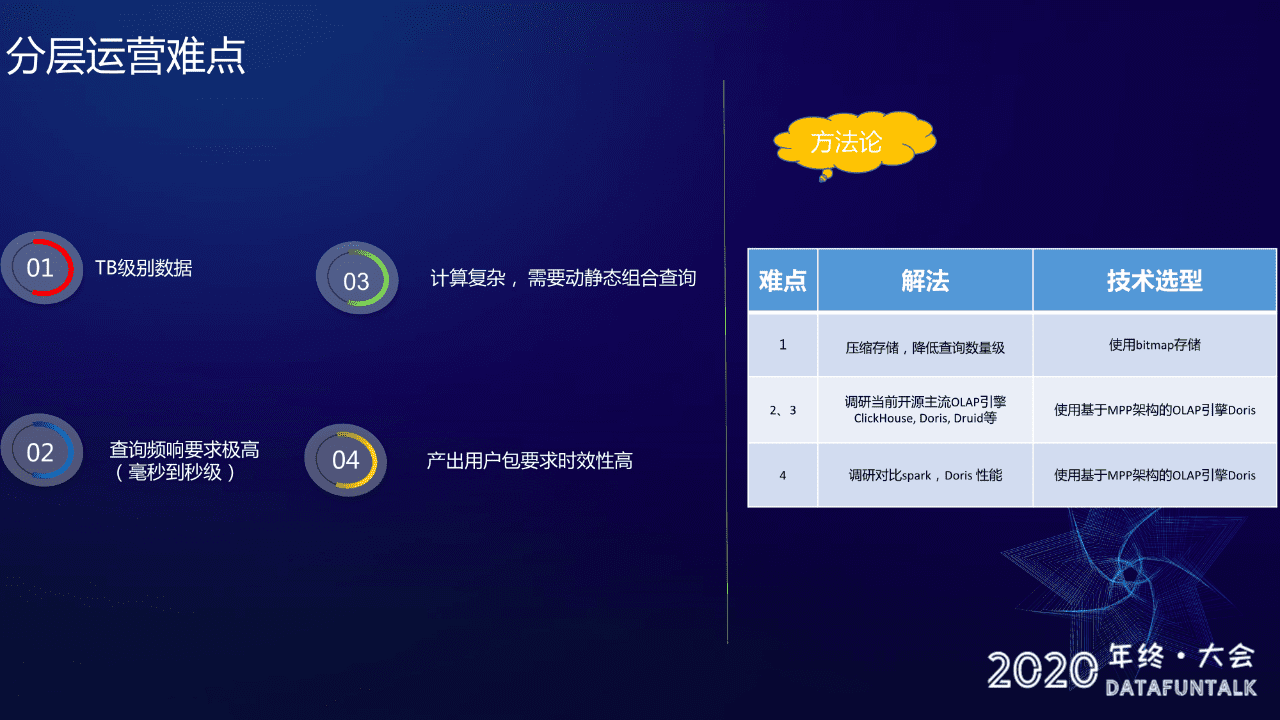
首先给大家简单介绍遇到的四个难点:
- TB级数据。数据量特别大,前面讲到我们是基于画像和行为去做的一个用户分层,数据量是特别大的,每天的数据量规模是 1T +
- 查询的频响要求极高,毫秒级到秒级的一个要求。前面介绍 B 端视角功能时大家有看到,我们有一个预估人数的功能,用户只要点击 ”预估人数“ 按钮,我们就需要从 TB 级的数据量级里面计算出筛选出的人群人数是多少,这种要在秒级时间计算 TB 级的数量的一个结果的难度其实可想而知
- 计算复杂,需要动静组合。怎么理解?就是现在很多维度我们是没办法去做预聚合的,必须去存明细数据,然后去实时的计算,这个后面也会细讲
- 产出用户包的时效性要求高。这个比较好理解,如果产出特别慢的话,肯定会影响用户体验
针对上面的四个难点,我们的解法是:
针对第一个难点 --> 压缩存储,降低查询的数量级。
具体选型就是使用 Bitmap 存储,这解法其实很好理解,不管现在主流的 OLAP引 擎有多么厉害,数据量越大,查询肯定会越慢,不可能说数据量越大,我查询还是一直不变的,这种其实不存在的,所以我们就需要降低存储。
针对第二和第三个难点 --> 选择合适计算引擎
我们调研了当前开源的包括 ClickHouse, Doris, Druid 等多种引擎,最终选择了基于 MPP 架构的OLAP引擎 Doris。
这里可以简单跟大家介绍一下选择 Doris 的原因,从性能来说其实都差不多,但是都 Doris 有几个优点:
- 第一:它是兼容 Mysql 协议,也就是说你的学习成本非常低,基本上大家只要了解mysql, 就会用Doris, 不需要很大的学习成本。
- 第二:Doris 运维成本很低,基本上就是自动化运维。
针对第四个难点 --> 选择合适的引擎
通过对比 Spark 和 Doris,我们选择了 Doris ,后面会详细讲为什么会用 Doris。
03用户分层的架构和解决方案
介绍难点以及解法之后,接下来从架构跟解决方案里面跟大家细讲一下,难点是怎么解决的。
分层运营架构:
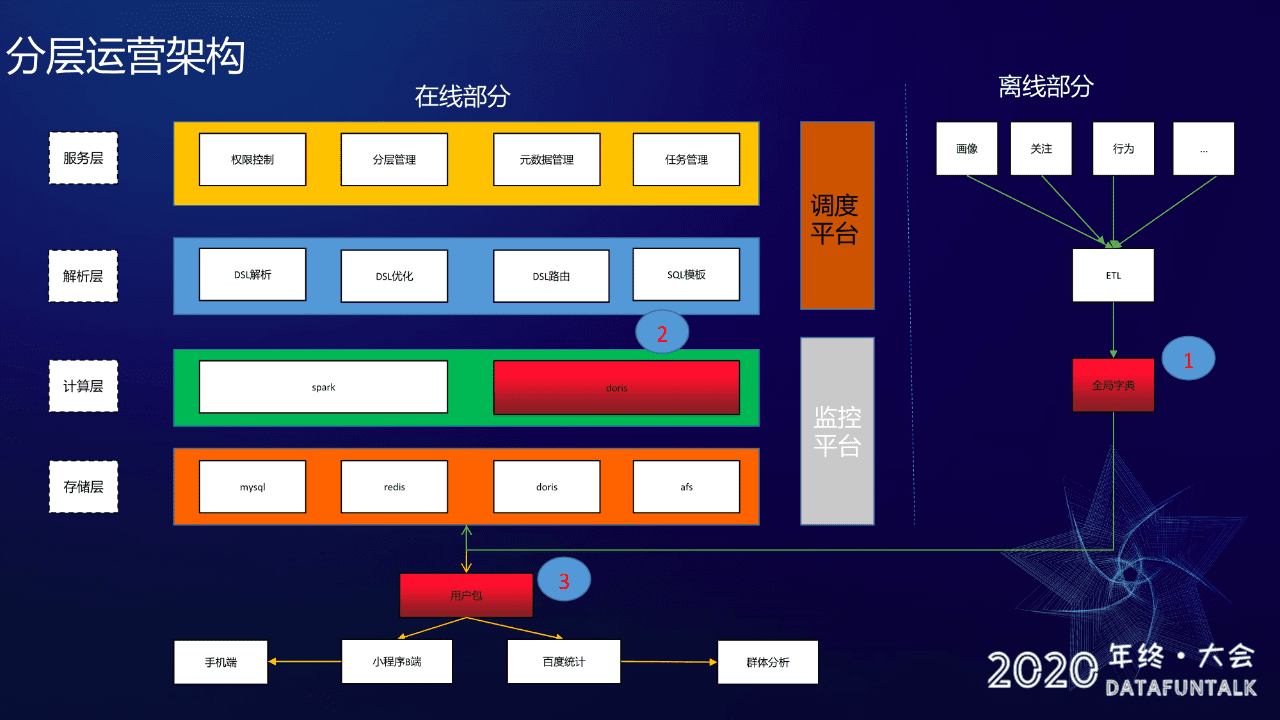
首先介绍一下我们分层运营的架构。架构的话分为两部分,就是在线部分跟离线部分。
在线部分:
分为了四层:服务层、解析层、计算层跟存储层,然后还有调度平台和监控平台。
服务层,主要功能包含:
- 权限控制:主要是户权限、接口权限的控制
- 分层管理:主要是是对用户筛选的增删改查
- 元数据管理:主要是对页面元素、ID-Mapping 这类数据的管理
- 任务管理:主要是支持调度平台任务的增删改查
解析层,是对DSL的一个解析、优化、路由以及Sql模板:
比如要查在线预估人数,首先会在解析层做一个 DSL 的解析,之后根据不同情景做 DSL 的优化,比如选择了近七天活跃且近七天不活跃的用户,这种要七天活跃和七天不活跃的交集显然就是零了,对不对?像这样情况在优化层直接将结果 0 返回给用户就不会再往下走计算引擎,类似还有很多其他优化场景。然后优化完之后会使用 DSL 路由功能,根据不同查询路由到不同的 Sql 模板进行模板的拼接。
计算层,计算引擎我们使用 Spark 和 Doris:
- Spark:离线任务
- Doris:实时任务
存储层:
- Mysql:主要用来存用户分层的一些用户信息
- Redis:主要用作缓存
- Doris:主要存储画像数据和行为数据
- AFS:主要是存储产出的用户包的一些信息
调度平台:
- 主要是离线任务的调度
监控平台:
- 整个服务稳定性的监控
离线部分:
离线部分的话主要是对需要的数据源(比如说画像、关注、行为等数据源)做 ETL 清洗,清洗完之后会做一个全局字典并写入 Doris。任务最终会产出用户包,并会分发给小程序 B 端跟百度统计:
- 小程序 B 端:推送给手机端用户
- 百度统计:拿这些用户包做一次群体分析
以上就是一个整体的架构。
图中大家可以看到有几个标红的地方,同时也用数字 1、2、3 做了标记,这几个标红是重点模块,就是针对于上面提到的四个难点做的重点模块改造,接下来会针对这三个重点模块一一展开进行讲解。
1. 全局字典
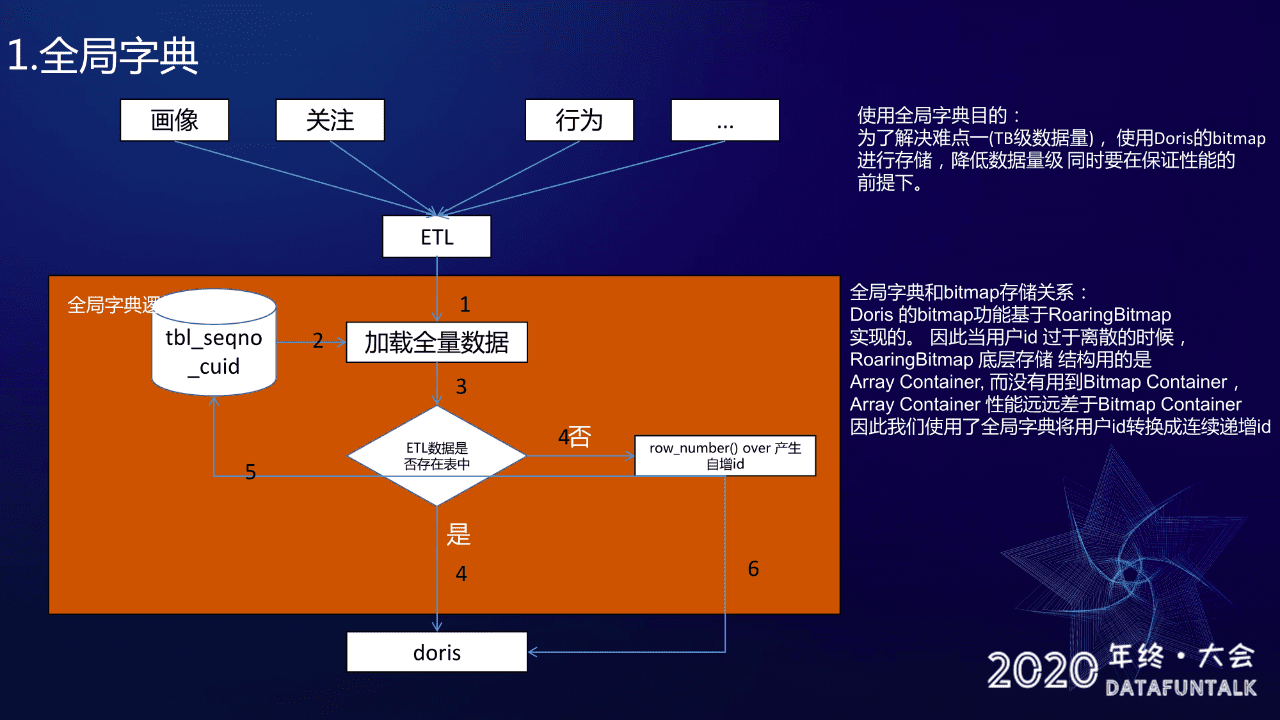
首先讲解全局字典这个模块,全局字典的目的主要是为了解决难点一:数据量大,需要压缩存储同时压缩存储之后还要保证查询性能。
为啥要用全局字典:
这里大家可能会有一个疑问,就是说我用 BitMap 存储为啥还要做全局字典?这个主要是因为 Doris 的 BitMap 功能是基于 RoaringBitmap 实现的,因此假如说用户 ID 过于离散的时候,RoaringBitmap 底层存储结构用的是 Array Container 而不是 BitMap Container,Array Container 性能远远差于 BitMap Container。因此我们要使用全局字典将用户 ID 映射成连续递增的 ID,这就是使用全局字典的目的。
全局字典的更新逻辑概况:
这里是使用 Spark 程序来实现的,首先加载经过 ETL 清洗之后各个数据源(画像、关注、行为这些数据源)和全局字典历史表(用来维护维护用户 ID 跟自增 ID 映射关系),加载完之后会判断 ETL 里面的用户ID 是否已经存在字典表里面,如果有的话,就直接把 ETL 的数据写回 Doris 就行了,如果没有就说明这是一个新用户,然后会用 row_number 方法生成一个自增 ID ,跟这个新用户做一次映射,映射完之后更新到全局字典并写入 Doris。
2. Doris
接下来介绍第二个重点模块 Doris。
2.1 Doris 分桶策略
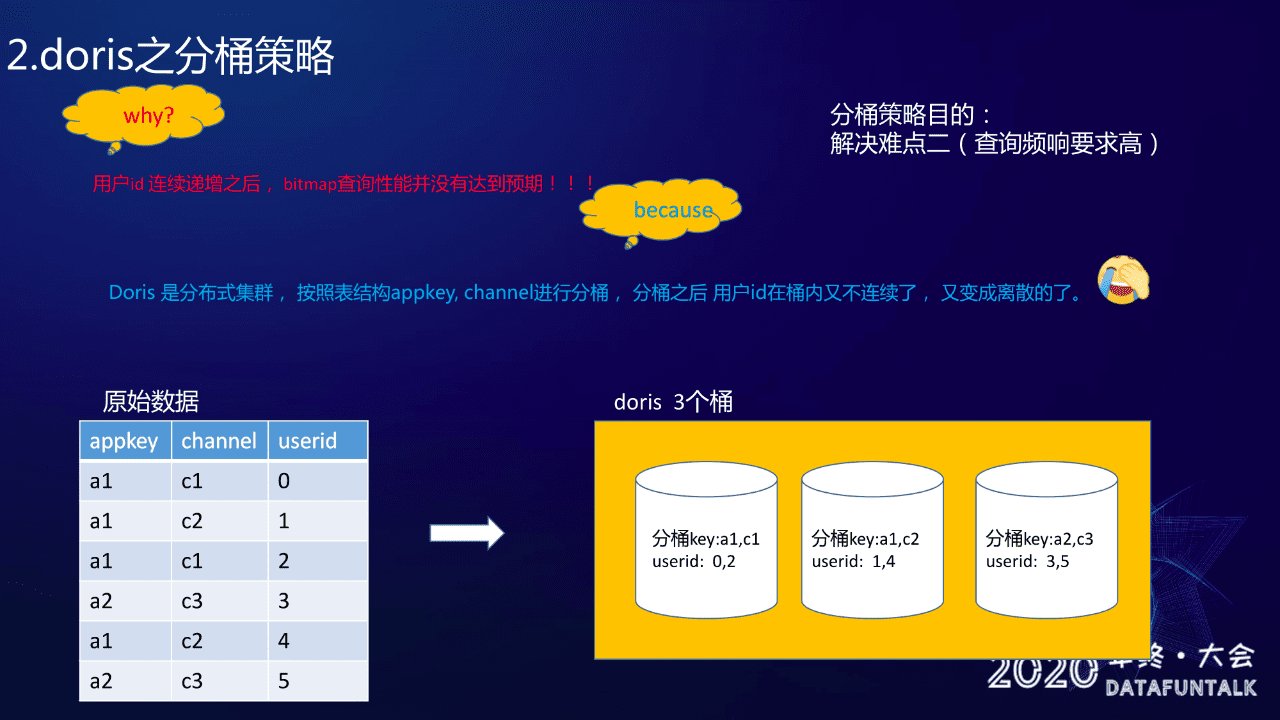
分桶策略的目的是为了解决难点二:查询频响要求高。
为啥要做分桶策略:
我们之前使用了全局字典保证用户的连续递增,但是我们发现用了全局字典之后,BitMap 的查询性能其实并没有达到我们预期的那样丝滑般柔顺的感觉,哈哈哈。。。对,还是特别慢,然后我们就特别郁闷了,开始怀疑 BitMap 并不像传说中的那么快,难道童话都是骗人的吗?我们就在想怎么解决这个问题,后来我们发现 Doris 其实是分布式的一个集群,它会按照某些 Key 进行分桶,也就是分桶之后用户ID 在桶内就不连续,又变成零散的了。
举个例子,如图中左侧原始数据,可以看到 appkey 有A1、A2,channel 有C1、C2、C3,然后 userid 是0、1、2、3、4、5 六个连续的 userid 。我们按照 appkey 和 channel 进行分桶,这样的话分完桶之后的结果就是右边这张图:桶一 key 是A1、C1,userid 就是0、2;桶二 key 是 A1、C2,userid 就是 1、4;桶三 key 是A2、C3,userid 是3、5;大家能比较直观地看到在桶中 userid 已经不连续了,不连续的话,BitMap 的性能就没法发挥出来的,它会走 Array Container 去存储,它的性能会比较差。
解决方式:
这里,其实我想问一下大家,这种怎么去保证桶内的连续?大家如果有想法,可以私下一起讨论下,现在大家不要给自己加戏啊, 今天的star是我啊, 大家要focus on me 身上啊。开个玩笑啊, 活跃下直播间气氛。
接下来我会跟大家分享一下我们的一个方案,对了,给大家五秒钟的时间,大家可以现在记笔记了,真的,这个方案是我们经历了无数个日日夜夜跟无数根头发总结出来的,非常有实战意义。
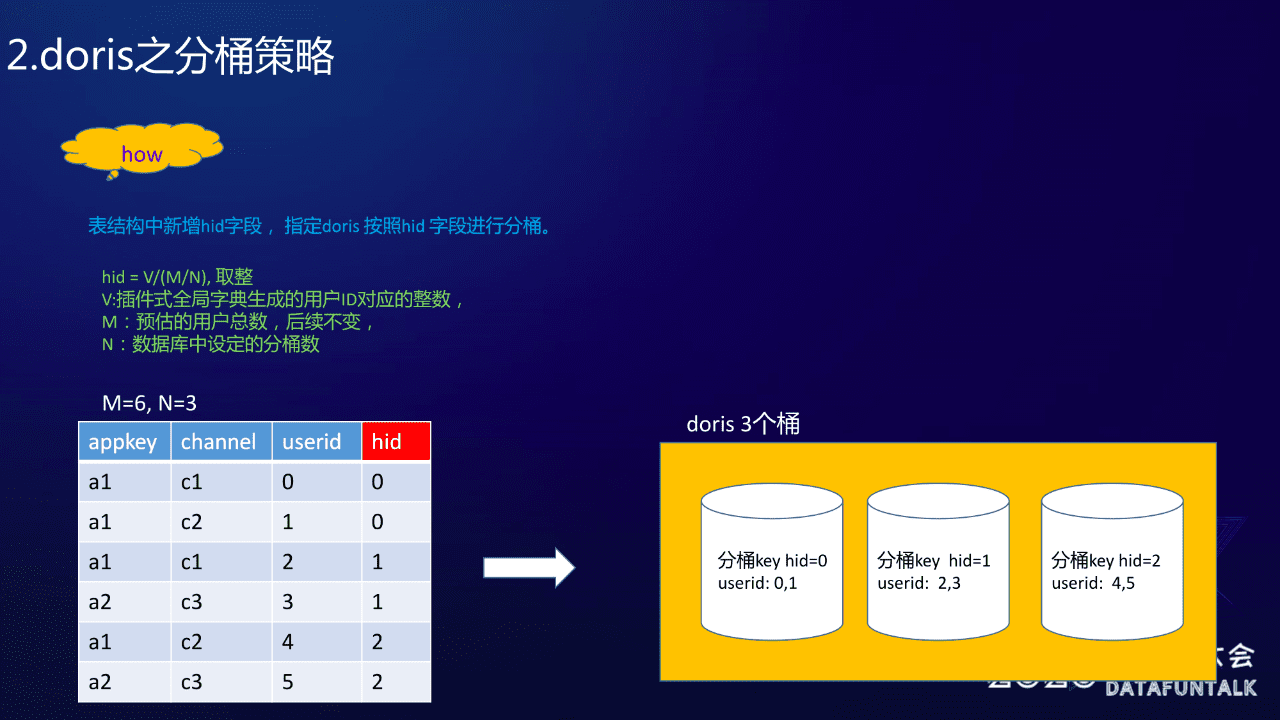
好,现在讲一下我们的方案,我们的方案是在表里面增加了一个 hid 的字段,然后让 Doris 按照 hid 字段进行分桶,这里 hid 生成算法是:
hid = V/(M/N) 然后取整
其中:
- V:全局字典的用户ID 对应的整数
- M:预估的用户总数
- N:分层数
还是结合上面的例子,大家可以看一下:userid 是六个即 0~5,所以 M= 6;分为三个桶,N = 3;因此 M 除以 N 就等于二。这样的话我就要用 userid 去除以二,然后取整作为 hid。可以看一下,比如说 userid 是零,0÷2 取整为 0 ,userid 是一的话,hid 还是这样,因为 1÷2 的整数部分是零;同理 2÷2 、3÷2 是一,4÷2、5÷2 是二,这样的话就把 userid 跟 hid 做对应,然后再根据 hid 做分层。大家可以看到分层结果,hid = 0 时 userid 是0、1,hid = 1 时 userid 是2、3,hid = 2时 userid 是 4、5,这样就保证了桶内连续。
2.2 doris之用户画像标签优化

前面给大家讲了分桶与全局字典这两个通用的策略,就是说大家要做 BitMap 的话,这两个东西肯定是要考虑的,但是只考虑这两个东西,还并不能说达到性能的最优,还要结合自己的实际业务去做针对性的优化,这样才能达到一个性能的最优,接下来我会给大家介绍我们的具体业务优化:画像标签的优化。
画像标签优化解决的难点也是难点二:查询频响要求高。这个问题当时是有两个方案。
方案一:
tag_type, tag_value 。tag_type 是用来记录标签的类型,tag_value 是用来记录标签的内容。
如图所示:比如说 tag_type 是性别,tag_value 可能是男或女,bitmap 这里就是存储所有性别是男的用户 id 列表。
同样对于 tag_type 是地域、tag_value 是北京,bitmap 存储的是所有地域在北京的用户 id 列表。
方案二:
大宽表,使用大宽表在一行记录了所有的标签,然后使用 bitmap 记录这个标签的用户 id 列表。
最终我们选择了方案二,为什么没有选方案一呢 ?因为方案一它是一个标签对应一个用户 bitmap,当我想查一个联合的结果就比较耗时,比如我想查询性别是男且区域是北京的所有用户,这样的话我需要取出 “男” 的用户和 “北京“ 的用户,两者之间做一个交集,对吧?这种的话肯定会有计算量会有更多的时间消耗,但是如果用大宽表去做存储的话,就可以根据用户常用的查询去构建一个物化视图,当用户的查询(比如在北京的男性)命中了物化视图,就可以直接去取结果,而不用再去做计算,从而降低耗时。
这里还有一个知识点跟大家分享一下:在使用 Doris 的时候,一定要尽量去命中它的前缀索引跟物化视图,这样会大大的提升查询效率。
2.3 doris之动静组合查询

好,用户标签讲完之后继续讲下一个难点的解决方案:动静组合查询,对应的难点是难点三:计算复杂。
首先介绍一下什么叫动静组合查询:
- 静态查询:我们定义为用户维度是固定的,就是可以进行预聚合的查询为静态查询。比如说男性用户,男性用户个就是一个固定的群体,不管怎么查用户肯定不会变,就可以提前进行预聚合的。
- 动态查询:主要偏向于一些行为,就是那种查询跟着用户的不同而不同。比如说查近30天收藏超过三次的用户,或者还有可能是近30天收藏超过四次的用户,这种的话就很随意,用户可能会查询的维度会特别的多,而且也没法没办法进行一个预聚合,所以我们称之为动态的一个查询。
然后小程序用户分层,相比于同类型的用户分层功能增加了用户行为筛选,这也是小程序产品的特点之一。比如说我们可以查近 30 天用户支付订单超过 30元的男性, 这种 ”近 30天用户支付订单超过 30元“ 的查询是没办法用 bitmap 做记录的,也没办法说提前计算好,只能在线去算。这种就是一个难点,就是说我怎么用非 bitmap 表和 bitmap 做交并补集的运算,为了解决这个问题,我们结合上面的例子把查询拆分为四步:我要查近30天用户支付订单超过30元的男性,且年龄在 20 ~30 岁的用户(具体查询语句参考 PPT 图片)
第一步我先查 20~30岁的男性用户。因为是比较固定,这里可以直接查 bitmap 表,
第二步我要查近30天用户支付订单超过30元的用户。这种的话就没办法去查 bitmap 表了,因为 bitmap 没有办法做这种聚合,只能去查行为表。
第三步就是要做用户ID 跟在 线 bitmap 的一个转化。Doris 其实已经提供了这样的功能函数:to_bitmap,可以在线将用户 id 转换成 bitmap。
第四步是求交集。就是第一步和第四步的结果求交集。
然后,请大家要注意一下,整篇的核心其实是在第三步:Doris 提供了 to_bitmap 的功能,它帮我们解决了非 bitmap 表和 bitmap 联合查询的问题。讲到这里,我其实想给大家表现出那种Doris特别惊艳、特别帅那种感觉,但是我线下练习了好多遍都无法表演出来, 你们看我现在的表演 有点太浮夸了, 用力过猛了。谁让我是个程序员,不是个演员呢,没有办法演出那种感觉、那种感情。所以我只能把我想表达的感情跟大家说出来,大家一定要懂我,对,就是那种很惊艳的感觉,大家一定要懂我~
以上是我们基于 Doris 用户分层方案的一个讲解,基于上述方案整体的性能收益是:
- 95分位耗时小于一秒
- 存储耗降低了9.67倍
- 行数优化了八倍
说明了基于 Doris 的用户存储方案还是特别有效果的, 希望我们的经验能给大家能有所帮助。
3. 如何快速产出用户包

现在讲一下第三部分:用户包。这部分主要是用来解决难点四:产出用户包要求时效性高。这个其实我们也有两个方案:
方案一:调度平台 + spark。
这个其实比较容易理解,因为你要跑离线任务很容易就想到了 spark。在这个调度平台里面用了 DAG 图,分三步:先产出用户的 cuid,然后再产出用户的 uid,最后是回调一下做一次更新。
方案二:调度平台 + solo。
- 执行的 DAG 图的话就是:solo 去产出 cuid,uid,还有回调。
- solo:是百度云提供的 Pingo 单机执行引擎,大家可以理解为是一个类似于虚拟机的产品,这个其实是公有云:《百度智能云》里面已经有的功能,大家感兴趣的可以去登录百度智能云官网 去看一下。
最终的方案选型我们是选用了 Doris,因为 Doris 比 Spark 更快,为啥快?
首先介绍下方案一,方案一使用的是 Spark ,它存在几个问题:比如 Yarn 调度比较耗时,有时候也会因为队列的资源紧张而会有延迟,所以有时候会出现一个很极端的情况就是:我产出零个用户,也要30分钟才能跑完,这种对用户的体验度非常不好。
方案二的话就是我们利用了 Doris 的 SELECT INTO OUTFILE 产出结果导出功能,就是你查出的结果可以直接导出到 AFS,这样的效果就是最快不到三分钟就可以产出百万级用户,所以 Doris 性能在某些场景下比 Spark 要好很多。
最后大家可以看到其实我这里叙述的时候语气依然是比较平淡的,是吧?没有带什么感情,但是我其实还想表达出那种惊叹和喜悦的感情,就是 Doris 性能在某些场景下比 Spark 还要好,但是大家要懂我,我毕竟是个程序员不是一个演员,没法表达出那种感觉,但是你们一定要懂我啊,哈哈,开个玩笑,活跃一下直播间气氛。
04未来规划

未来的规划:
首先在产品上我们会继续的丰富分层的应用场景,拓展关系维度丰富触达的形式,然后探索分层和商业的结合模式。
在技术上我们会从时效性丰富性跟通用性上做文章:
- 时效性:我们会把交易,订单,关注等行为时实化
- 丰富性:我们会接入更多的用户画像,标签和行为
- 通用性:我们会把全局字典插件化,然后通用到各个业务上
这就是我们的未来规划。后面有机会再根大家从 Doris 的架构方面跟大家介绍下 Doris 的性能为何如此强悍。今天的分享就到这里,谢谢大家。
—— 欢迎在线投稿 ——
特别提示:关注本专栏,别错过行业干货!
PS:本司承接 小红书推广/抖音推广/百度系推广/知乎/微博等平台推广:关键词排名,笔记种草,数据优化等;
咨询微信:139 1053 2512 (同电话)
首席增长官CGO荐读:
更多精彩,关注:增长黑客(GrowthHK.cn)
增长黑客(Growth Hacker)是依靠技术和数据来达成各种营销目标的新型团队角色。从单线思维者时常忽略的角度和高度,梳理整合产品发展的因素,实现低成本甚至零成本带来的有效增长…
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/user/37464.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫