相信任何一位有互联网公司工作经验的同学对“A/B 测试”这个概念一定不陌生,简单理解就是将用户随机分成实验组和参照组,然后让两组用户分别使用改版后和改版前的产品,最后对实验结果进行分析比较,如果实验组结果较好,则全量推广改版后的产品,否则就维持旧版不动。这样理解完全没毛病,但这只是 A/B 测试的最基本的概念,这篇文章通过在 To C 业务的实践跟你聊聊你不知道的 A/B 测试。
1. 只有互联网公司才会用 A/B 测试吗?
如果你认为只有互联网公司才会用 A/B 测试,那就大错特错了。其实在我们的日常生活中,A/B 测试非常常见,举两个例子让大家感受一下。
1.1 物竞天择,适者生存
最早使用 A/B 测试的是大自然,想象不到吧?我们知道物种的遗传靠基因,但基因有两种特性,一是忠实地复制自己以保持生物的基本特征,所以才会龙生龙,凤生凤,老鼠的儿子会打洞;另一个特性是基因突变,当受到环境等因素影响时,基因可能会发生突变。但谁也不清楚这种突变是好还是坏,有可能基因突变导致了镰刀型细胞贫血症,这是一种红细胞由正常的圆饼状变成镰刀型,导致红细胞不能顺利聚集在一起,从而造成贫血的一种恶性基因突变;但也有可能导致长颈鹿的脖子越来越长,可以够得着高处的树叶,不至于在地面植物越来越稀少的环境下饿死。
这不正是大自然做的 A/B 测试实验吗?那些复制自己保持生物基本特性的群体就是参照组,而那些基因突变的群体就是实验组,然后把两者放入到真实的环境中测试,如果只有基因突变的群体活下来,说明实验组胜出,反之则实验组失败。
1.2 A/B 测试助力总统竞选
2008 年,奥巴马竞选美国总统成功,成为美国历史上第一位黑人总统,这背后纵然离不开他的个人魅力,但他的竞选团队在背后发挥的作用也是举足轻重的,其中的一个例子就是总统竞选官网的设计。

竞选团队一共设计了四款竞选官网封面图以及四款按钮文案(如上图所示),然后组合成 16 种官网样式,给予每种样式一定比例的流量,观察一段时间后,从中选择转化率最高的那个方案。最终胜出的方案是“家庭封面 + LEARN MORE”组合,这个方案最终将总统竞选页面的转化率提高了 40.6%。
2. 什么是 A/B 测试
通过两个例子,我们比较直观地认识了 A/B 测试,即将用户随机分成参照组和实验组,分别实验,最终选择效果较好的那一种方案。但如果深入研究,会发现另有一片天地。说了这么久,我们看看到底什么是 A/B 测试以及它能够做什么。
我们看下维基百科对 A/B 测试的定义:
A/B 测试为一种随机测试,将两个不同的东西(即 A 和 B)进行假设比较。该测试运用统计学上的假设检定和双母体假设检定。A/B 测试可以用来测试某一个变量两个不同版本的差异,一般是让 A 和 B 只有该变量不同,再测试其他人对于 A 和 B 的反应差异,再判断 A 和 B 的方式何者较佳。
这个定义里提到了 3 点,也是 A/B 测试的核心思想。
- 两个不同的方案:有对比才能辨别好坏,所以至少需要同时有两个不同的方案在并行运行;
- 一个变量:就是中学里经常提到的“控制变量法”,只有在单变量的情况下才能判定该变量的影响;
- 优良判断规则:设置一定的衡量指标,比如 PV、点击率等等,然后对比不同方案的指标情况,确定孰优孰劣。
那么哪些场景会用到 A/B 测试呢?从第 1 小节我们知道,A/B 测试的适用范围实在广泛,大到大自然的物种进化,小到个人的行为选择,我们把范围收一收,仅限于互联网公司内。那又会有哪些场景呢?那又得从互联网公司的各个方面来分析,比如广告营销,我们可以使用 A/B 测试来验证不同广告策略的效果;比如算法优化,我们可以使用 A/B 测试来比较不同模型或者参数对算法效果的影响;当然最常见的还是产品的更新迭代,我们会使用 A/B 测试来验证新的改动是否会带动数据的提升,那该如何做好 A/B 测试呢?
3. 如何做 A/B 测试
想要做好 A/B 测试,有六大要素,分别是实验基础、安全稳定、精确洞察、规模效率、特殊场景和实验文化,一一详细地聊聊。
3.1 实验基础
实验基础可以保证 A/B 测试的基本功能可用,主要包含以下几部分。
3.1.1数据上报与数据分析平台
巧妇难为无米之炊,数据上报是实验的基础,如果没有上报的数据,那么将无法分析实验数据,更别提比较实验的效果,所以我们需要业务进行数据上报。我们会根据需要确定上报的数据,PV/UV 是最基本的数据,有的还会包括关键元素的点击量、页面停留时长等等。
有了数据还不够,还需要数据分析平台,让我们可以在上面对数据进行分析。
3.1.2 分流器
虽然我们知道 A/B 测试就是将用户随机分为参照组和实验组,然后对比实验效果,那问题来了,参照组和实验组的用户怎么确定?又如何保证随机性?QQ 业务的用户有个天然的用户标识:QQ 号,那么我们就会自然地想到给 QQ 号取 100 的余数,余数相同的分为一组,那么就可以把所有的用户分成 100 组,我们拿出其中一组做对照组,再拿出一组用户做实验组。听起来是不是很完美?其实这里面还有一些问题。首先,QQ 号有靓号和非靓号的区别,比如 6666 开头的用户按照上面的规则都被分到了一组,靓号一般是需要购买的,所以靓号用户与普通用户在活跃度等方面存在着差别,那就无法保证用户的随机性以及实验因素的单一性;其次,按照上面的规则,所有用户最多被分成 100 组,那做了 100 次实验之后怎么办?所以这种方式还会导致实验组很快被消耗完。有人说,可以把其中被用过的一组放置一段时间,消除前一个实验的影响,那就会导致第三个问题:如果都用第 6 组作为实验组,即使前一次实验被放置了一段时间,那么你怎么就能确定数据变化是这次还是上次的实验造成的呢?所以为了解决这三个问题,A/B 测试分流器必须要同时满足三个条件:随机性、无限性和互不干扰性。
随机性
随机性需要保证用户的分组必须充分随机,不能造成具有相同属性的用户扎堆,比如 QQ 取余的方式就会导致靓号扎堆。那怎么保证随机性呢?一种解决方案就是使用哈希函数。
无限性
所有的 QQ 号被哈希函数打散后分成若干组,无论分成多少组,总会被用完的,那如何实现无限分组呢?我们只需要对所有用户重新洗牌分组即可。有两种方式,我们可以换一种哈希函数,但每次都要换一种哈希函数比较麻烦,另一种就比较简单,使用同一种哈希函数,但每次洗牌时将放入不同的标识作为 salt。
互不干扰性
将用户重新打散的方式能否一定保证实验组之间互不干扰呢?我们洗牌的时候有时会发现牌没洗完全,导致上一局某个人的很多牌在这一局中到了另一个人手里。那对全体用户重新打散时会不会也出现这种情况:上一次的第 66 号组的大多数用户被分到了这次的 88 号组里面?这种情况是可能的,如何避免呢?使用流量正交,即把上一次每一组的用户平均分到新的分组中,比如上一次的 1 号组的所有用户会被均匀打散到这次的所有组里面去。
3.1.3 A/B 测试配置系统
分流器可以将用户均匀随机分组,但具体的哪次产品改动对应哪组实验组,这需要专门的配置系统。
3.2 安全稳定
有了实验基础的几个部分,我们便可以开展 A/B 测试实验了,但线上的产品可不能仅仅能用就行,还要考虑安全稳定。这里的安全稳定不仅仅是 A/B 测试相关系统的安全稳定,另一方面也指对测试的业务影响应该尽量小,如果一次实验导致大盘总体的核心指标下降 5%,那影响就非常大了。
那该如何保证 A/B 测试的安全稳定呢?有几个方面。
首先 A/B 测试系统应该支持灰度递增,比如一开始仅拿 1% 的流量进行实验,在确定对大盘没有负面影响或者有正面影响时,在慢慢递增灰度数量。如果一上来就拿 20% 甚至更多的量做实验的话,那很有可能会大盘数据造成影响。
其次我们需要监控关键指标,我们需要设置一些关键指标并且对这些指标进行监控,比如给 DAU 设定一个阈值,当实验时的阈值低于这个值时,那就停止相关实验,等待分析和处理后再重新实验。
最后需要对 A/B 测试系统做一些限制,比如不允许灰度时直接放量到 100%。
3.3 精确洞察
在 A/B 测试系统功能可用并且安全稳定的前提下,我们就需要考虑对实验数据的精确洞察。
首先需要进行实验质量测试,检测数据是否可信,如果上报的数据不可信,那下面的分析比较都是徒劳的。
其次对于一些复杂场景的 A/B 测试来说,还需要做一些额外的工作进行数据洞察,比如需要进行用户细分群组分析、分层抽样、归因分析等等,因为 To C 业务中主要针对单个改动进行 A/B 测试,所以这里不赘述复杂场景的数据洞察方法。
然后我们还要制定实验规范和审核机制,即使实验系统比较完善,但如果操作不规范也有可能导致实验故障。
3.4 规模效率
接下来我们要考虑如何提高规模效率,我们希望支持尽可能多的实验同时进行,也希望用尽可能少的样本得到更多的信息。
在“实验基础”部分我们提到过,A/B 实验的分流器应该满足随机性、无限性和互不干扰性三个特性,其中的无限性指的是应该支持对有限的用户进行无限的分组,以保证实验组充足可用。
如果实验之间互不影响,那只要实验组充足也就够了。如果是多个实验并行并且互相之间有影响,或者一个实验里面有多个影响因素,那这种情况应该怎么办呢?业界像 Google、微软对此都有一些研究,比如方差减少方法、多臂老虎机等等,这里也不再赘述。
3.5 特殊场景
正常情况下,如果 A/B 测试系统能够包含以上四个部分,那么已经非常完备了,但是还有一些特殊场景也会影响到 A/B 测试系统的设计,这里简单提一下。
首先是网络效应。我们做 A/B 测试实验时默认用户与用户之间是独立,比如我所处的信息流业务,绝大部分情况下,消费信息流是用户的独立行为。但是还有一些像微信、QQ 这样的社交业务,用户与用户之间互相影响,参照组和实验组的用户可能互相干扰,那么在设计实验时就要考虑这些。
其次是因果推断。这经常发生在无法随机分配用户的情况下,比如雾霾期间你出门,你可能戴了口罩也有可能没戴,戴或者不戴你只能选择一个。这种情况下,用户只有你一个人,再来一个人同时观察行不行,不行,因为两个人的自身情况可能不一样;那我今天和明天两天对比行不行,也不行,今天和明天的雾霾情况可能会有差异。所以这类问题是有多个潜在结果,但你只能观测到一种,其他情况只能推测。
还有增量模型。增量模型指的是利用机器学习和实验进行有成本的营销策略,比如在预算固定的情况下如何最大化市场营销效果。
3.6 实验文化
如果说前五个部分能够代表一个团队的 A/B 测试的硬实力的话,那么实验文化就是软实力了。
团队应该营造一个数据驱动文化,知道什么是 A/B 测试实验,什么时候该用 A/B 测试实验等等。另外团队成员之间还应该经常互相分享实验案例和经验,交流趟过的坑、有没有更好的实验方法,还可以交流一些行业前沿的成果等等。
4. 腾讯看点信息流的 A/B 测试实践
随着 2019 年 11 月份腾讯看点的成立,原本独立的 QQ看点、QQ浏览器、看点快报进行了整合,三端的更新迭代也趋于统一,功能研发也有序统一推进,其中一个便是短内容的研发。
所谓短内容,从字面理解就是内容短小精悍的内容。与传统的图文并茂、花样复杂的信息流内容相比,短内容具有低门槛、快消费、易传播等特点。腾讯看点的短内容原本只有“搞笑”这一个品类,但随着业务发展,发现越来越多的品类可以以短内容的形式展现,所以产品提出“短内容支持多品类”需求。
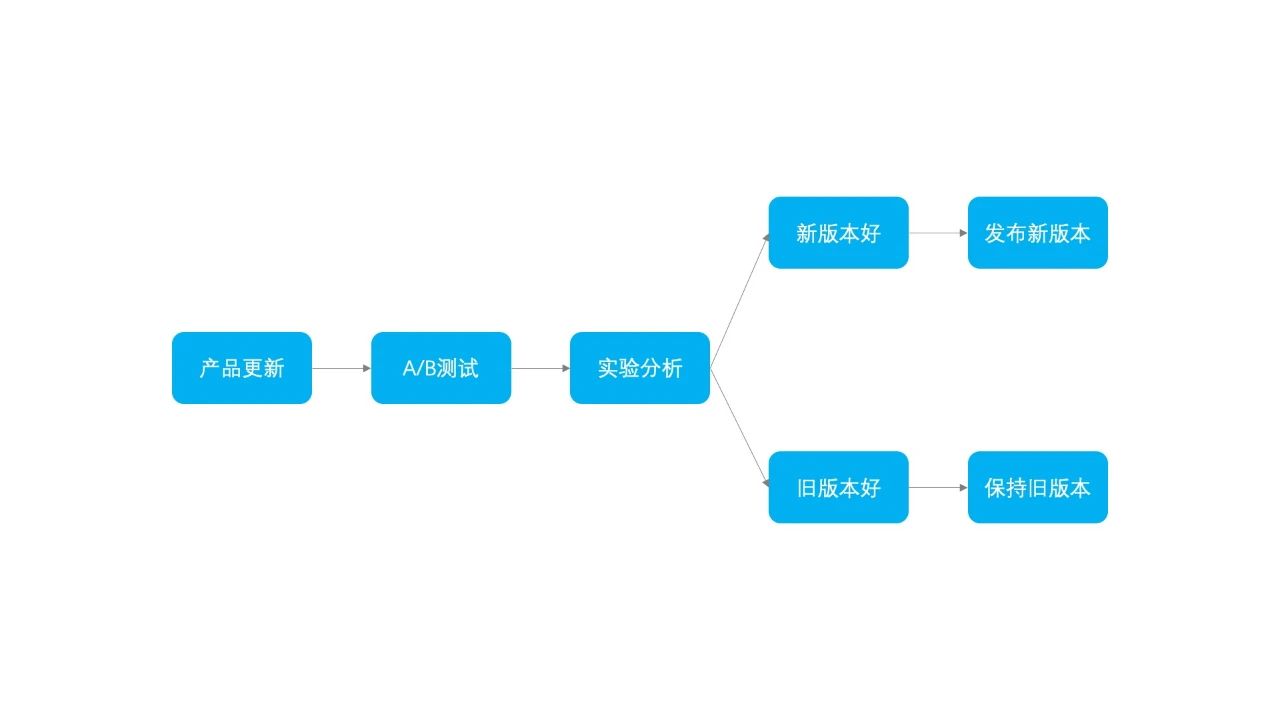
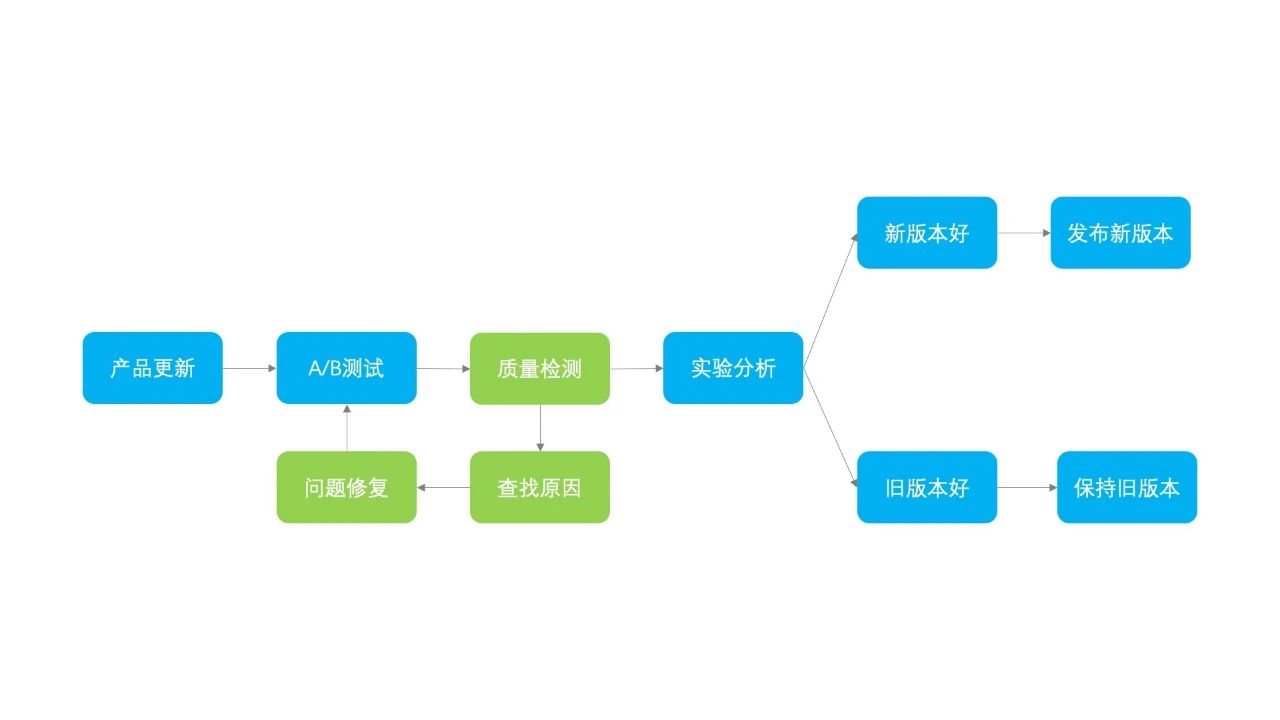
在功能开发完成后,下一步就是 A/B 测试环节,验证用户是否喜欢新功能以及新功能对关键数据的影响。理想的步骤应该就是进行 A/B 测试实验,然后进行实验分析,判断实验好坏,如果新版本效果较好那么就选择新版本,否则就维持旧版本,如图所示。
在上了多品类类型的短内容后,A/B 测试的实验结果显示实验组每天的时长均比参照组高 15%!看到这样的数据,你的第一反应是什么:新功能有更好的效果。如果你这样想,那表示你的 A/B 测试的能力还处于刚入门的水平。我们先别急着对比分析,而是要先检查数据是否正确。一般会有什么原因导致数据质量出现问题呢?
可能是分流系统,比如哈希函数导致分流不随机;可能是实验人员操作不规范,导致实验组不仅受本次实验影响还收到其他实验的影响;可能是数据上报的问题,因为数据上报口径不一致导致数据有差异;也有可能是用户的问题,比如大量的网络爬虫导致数据异常。也就是说,A/B 测试的任何环境都有可能导致数据质量出现问题,那有什么检查数据质量的方法吗?
这里有两个方法。一是 A/A 测试,通过给参照组和实验组配置一样的功能,然后测试实验数据是否有显著偏差,如果出现了显著偏差,那说明数据质量肯定是有问题的;二是样本比例测试,实验组和参照组的样本比例一般是 1:1,如果两者显著不等于 1:1,那说明其中一个用户组丢失了一部分用户。
所以,当我们发现实验组的用户时长每天比参照组都要高 15% 时,我们对数据质量进行了检测,最终发现原来是两者的数据上报口径存在差异,一个是把内容中线的曝光和隐藏的间隔作为时长,另一个则是把内容卡片的曝光和隐藏的间隔作为时长。
因此,当进行完 A/B 测试后,先不要急着分析下结论,一定得确保实验数据质量。这时,我们更新下 A/B 测试的流程。
在确定了数据质量可靠的情况下,下面就需要对数据进行分析。根据 A/B 测试的目的或者业务类型的不同,用来衡量实验效果的核心指标也不同。大部分互联网产品会以用户指标为核心指标,比如用户次留、PV、UV、点击率、使用时长等等;有的特殊的互联网产品,比如电商网站会有一些其他的核心指标,比如下单率、评分、联系客服量等等。
确定了实验的核心衡量指标,下面就可以进行实验分析了。如果发现实验组的指标比参照组有所提升,即使有很细微的提升,那也是算是一个比较令人欣慰的现象,代表新的改动对数据增长有正向效果。但一般情况下,比较少有实验能够起到正向效果,或者说需要经过多次的改动后才能迎合用户。那如果我们发现实验效果是负向的,那该如何做呢,真的就像流程图里面画的那样“保持旧版本”吗?
相信大部分人肯定不会立马决定放弃新版本的,一方面新版本注入了大家的心血,直接舍弃太可惜,另一方面新版本代表未来趋势。所以在发现用户更喜欢老版本时,我们应该想办法改进新版本。这里介绍一种“用户细分群组分析”的方法。
所谓用户细分群组分析,就是根据用户的使用产品的用途将用户进行分组,尝试分析哪部分用户受影响最大,找出并解决他们的痛点。具体方法如下:1)用户分组:用聚类模型根据用户的用途将用户分组;2)分组实验分析:分析哪些用户组是整体指标下降的来源;3)重点组内分析:对重点用户组,分析用户的行为痛点;4)定位痛点:根据数据洞察,在产品设计层面下定位痛点;5)改进迭代:针对痛点进行改进;6)重新实验:开展新一期的实验,验证改进是否用帮助。
在腾讯看点短内容引进“长内容”类型的内容时,发现实验组的核心数据要比参照组少 0.6% 左右。这里先普及下背景,短内容页面的内容大多是图文,即上面是文字下面是图片的组合,短内容的文字一般不超过 6 行,而长内容的文字行数不限。在引进“长内容”时,我们默认将文字展开,对于数据的下滑,我们认为长内容的文字部分较长,会减少其他内容的曝光,所以设置了一条规则,长内容的文字部分超过 6 行则折叠,然后重新上线实验,果然数据又恢复了正常。
在实验分析阶段,我们了解到当新版本没有满足预期效果时,我们需要对新版本进行迭代更新。我们再次完善 A/B 测试的流程:
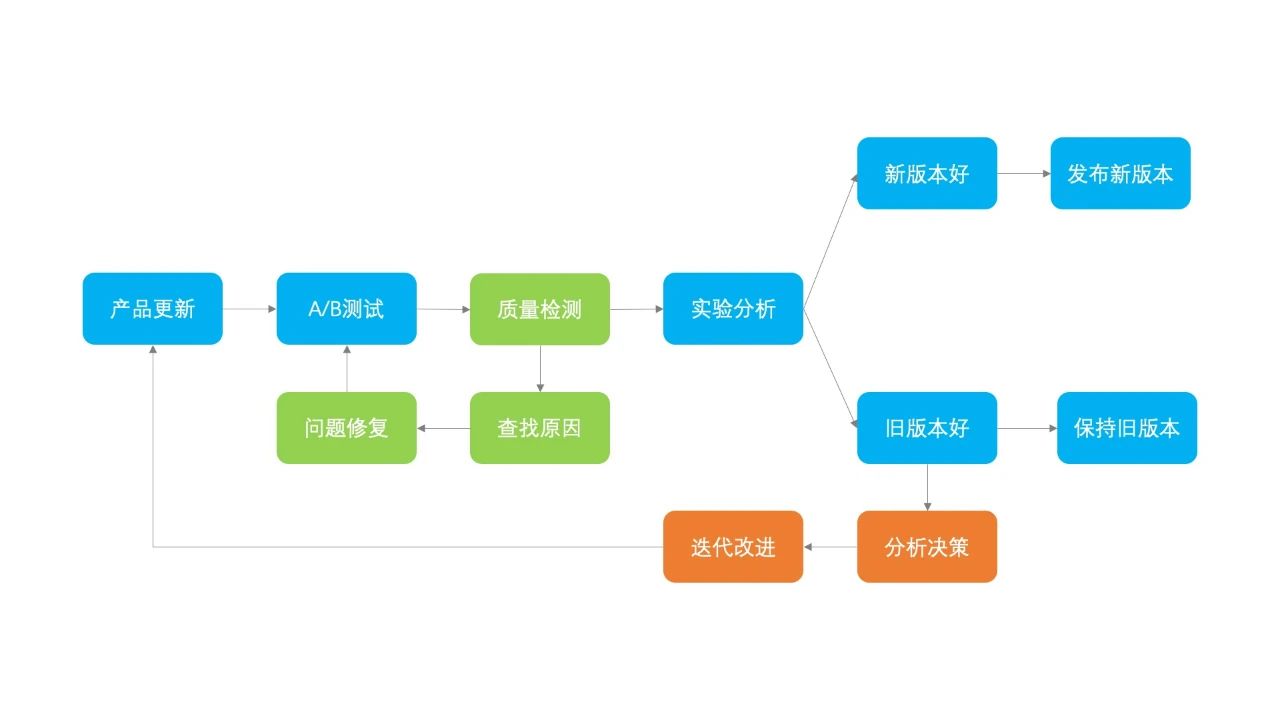
在确定发布新版本后,我们便开始进行灰度发布。发布前期的节奏一般较慢,从 1% 放量到 10% 需要半天左右的时间,放量过程中需要保持对数据的监控,在确认没有问题后,会很快地从 10% 放量到 99%,保留 1% 的用户在参照组继续观察,一周后 100% 全量。
5. 小结
本文主要介绍了 To C 业务的 A/B 测试。一个完善的 A/B 测试需要包含六个要素:实验基础、安全稳定、精确洞察、规模效率、特殊场景和实验文化,每个要素依次递进;然后以腾讯看点信息流业务举例,完善了 A/B 测试的流程,A/B 测试不仅仅只是简单的对比实验组和参照组效果,还需要在完成实验后对数据质量进行检查,以及在实验分析后进行分析决策,如果新版本的效果不理想还需要迭代改进。
文源:FEPulse
特别提示:关注本专栏,别错过行业干货!
PS:本司承接 小红书推广/抖音推广/百度系推广/知乎推广:关键词排名,创意短视频,笔记种草,代写代发等;
咨询微信:139 1053 2512 (同电话)
首席增长官CGO荐读:
更多精彩,关注:增长黑客(GrowthHK.cn)
增长黑客(Growth Hacker)是依靠技术和数据来达成各种营销目标的新型团队角色。从单线思维者时常忽略的角度和高度,梳理整合产品发展的因素,实现低成本甚至零成本带来的有效增长…
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/31220.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫