我们知道 RFM 模型是客户分群的重要模型之一,它主要基于客户行为进行划分,识别客户价值情况,把客户划分为 8 种类型。
那么问题来了,一定要划分为 8 种客户类型吗?
在实际的客户体验管理过程中,并不是非得要这么做。比如,一些信用卡机构,只会把客户分为 4 种类型:逾期风险高,办理过分期交易;逾期风险中,频繁高额交易;逾期风险中低,频繁小额交易;逾期风险低,分期交易意向低。而某大型银行客户体量庞大,则会将客户分群超过 20 种类型,进一步精细化客户体验管理。
RFM 提供的是一种进行客户分群的思路,至于具体分群数,可以根据客户规模和业务目标而定。
本文将会基于之前新零售公司的数据集,结合 RFM 模型和 K-Means 聚类两种方式,依据客户数据表征的特性,找到合适的分群。
练习数据集和实现代码可以通过公众号后台回复【RFM】获取。
通过本文,你可以了解到:
- 1、聚类(clustering)
- 2、聚类基本思想
- 3、K-Means
- 4、K-Means 优缺点
- 5、RFM + K-Means 案例应用
- 6、小结
1、聚类(clustering)
聚类,就是按照某个特定标准(比如"距离准则"),将一个数据集划分为有意义不同的类型或组(簇),使得相似性尽可能大的客户被划分到同一群,同时在不同群间能表现出明显的差异性。
简言之,就是聚类后,同一类数据尽可能聚在一起,不同类的数据尽量分离。
对于不同客户特性的相似性,会依据观测客户间的距离进行度量,比如数学意义上的欧氏距离(euclidean distance)和基于相关性的距离(correlation-based distance)。
对于聚类和分类,两者之间是有一定的差别的,探讨这个问题需要先引入两个概念,监督学习(supervised learning)和无监督学习(unsupervised learning)。
分类会具备明确的规则和条件,像图书馆的藏书分类,按主题,按年代、地域、语言等等。以计算机的思维进行理解,即计算机可以从已知的训练数据集中进行"学习",从而获取对于分类逻辑的判别方法。当汇入未知类别的新数据进行分类时,可以依照训练所得的经验进行自动判断,而这种提供训练数据的过程通常叫做监督学习(supervised learning)。
而聚类没有确切的定义,并不会知道任何样本的类别标号。希望通过某种算法来把一组未知类别的样本划分成若干类别,期间不需要使用训练数据集进行学习。所以,聚类又被称为无监督学习(unsupervised learning)。
两者相比,聚类旨在验证数据之间的相似性或不相似性,更侧重于边界条件。
2、聚类基本思想
先看一个案例。在某年的美国总统大选中,候选人的得票数非常接近。相互竞争的候选人的普选票数 48.7% : 47.9%。这时候,如果有办法让 1% 的选民倒戈,将手中的选票投向另外的候选人,那么选举结果就会截然不同。
实际上,如果有针对性地妥善加以引导,少部分选民就会转换立场。尽管这类选举者占的比例较低,但当候选人的选票接近时,这些人的立场无疑会对选举结果产生非常大的影响。
首先收集选民的基本信息,听取选民声音中反馈满意或不满意的信息,因为选民关注的重要议题,很大可能左右选民的投票结果。
然后,将这些信息输入到某个聚类算法中。对聚类结果中的每一个群(最好选择最大群 ), 精心构造能够吸引该群选民的消息。
最后,开展竞选活动并观察上述做法是否有效,不断迭代调整,这就是聚类的大致原理。
对于一堆散落的点,先确定这些散落的点最后需要聚成几类,然后挑选随机挑选几个点作为初始中心点,再然后依据预先定好的启发式算法(heuristic algorithms)给数据点做迭代重置(iterative relocation),直到最后到达“类内的点都足够近,类间的点都足够远”的目标效果。
启发式算法主要包括了K-Means,及其变体K-Medoids、K-Modes、K-Medians、Kernel K-means等算法。
本次将会选择最为经典的 K-Means 聚类+ RFM 模型,其他算法会在后续文章中更新。
3、K-Means
K-Means 是一种迭代求解的聚类分析算法,由于它可以发现 K 个不同的群, 且每个群的中心采用群中所含值的均值计算而成,也称之为 K-均值。其中,群数 K 须由用户指定。
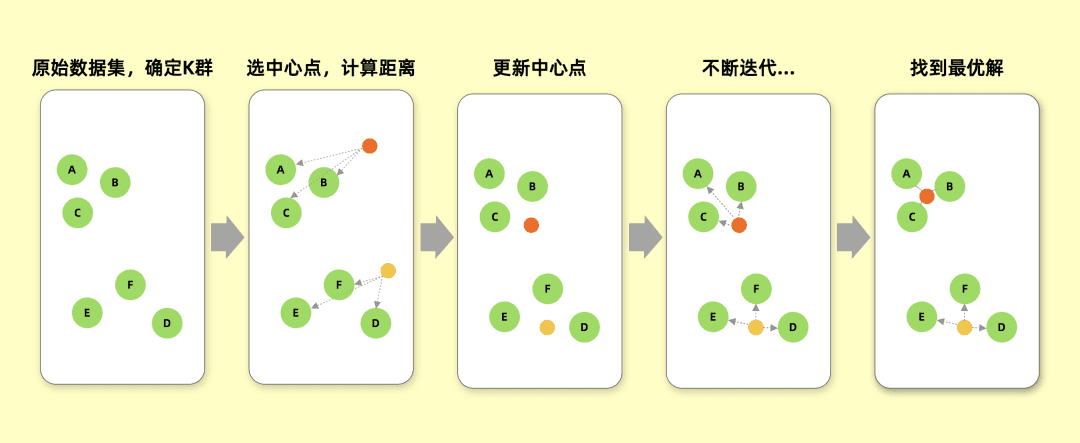
K-Means 聚类过程图解
算法流程如下:
- 1)随机选择 K 个初始点作为质心(不必是数据中的点),每个对象初始地代表了一个簇的中心;
- 2)对剩余的每个对象,根据其与各群中心的距离,将它赋给最近的群;
- 3)重新计算每个群的平均值,更新为新的群中心;
- 4)不断重复 2、3,直到数据集中的所有点都距离它所对应的质心最近时结束。
4、K-Means 优缺点
K-Means 优点在于原理简单,容易实现,聚类效果好,对于大型数据集也是简单高效、时间复杂度、空间复杂度低。
当然,也有一些缺点。需要预先设定 K 值,对最先的 K 个点选取很敏感;对噪声和离群值非常敏感;只用于 numerical 类型数据;不能解决非凸(non-convex)数据。受离群值影响大,最重要是数据集大时结果容易局部最优。
每种类型的算法都会有它的特点,都有侧重解决问题的面向。在应用之前,先理解不同算法的内在逻辑、作用、应用场景,结合实践经验,选出最合适的算法模型来达到业务目标。
5、RFM + K-Means 案例应用
练习数据集和实现代码可以通过公众号后台回复【RFM】获取。
笔者使用的是 R Studio 进行案例演示。如果你有其他的源数据,要想在 R Studio 中进行聚类分析,应该按照如下要求准备数据:
- 1) 行必须是观测值(个体或样本),列必须是变量。
- 2) 任何缺失数据都必须删除。
- 3) 必须对数据进行标准化。
步骤 1:
install.packages("factoextra")
install.packages("cluster")数据预处理完后,如果没有安装 factoextra(用于对聚类结果进行可视化) 、cluster(用以对数据进行聚类计算),需要先进行安装。
步骤 2:
#载入包
library(factoextra)
library(cluster)
#导入已经处理好的数据集 → RFM_Dataset.csv
rfm_data <- read.csv("/Users/guofu.long/Desktop/RFM_Dataset.csv", header = TRUE)
data_1 <- rfm_data[,1:4]
head(data_1)
#查看数据行列数、字符类型、描述性统计量
dim(data_1)
str(data_1)
summary(data_1)这里使用的 RFM_Dataset.csv 数据是在《应用 RFM 模型客户分群操作篇,提效客户体验管理》中处理好 RFM 对应值。导入数据后,对数据进行适当的观察,比如数据行列数、字符类型、描述性统计量等。
步骤 3:
data_2 <- data_1[,2:4]
#数据标准化
data_3 <- scale(data_2)
head(data_3)由于同一个数据集合中经常包含不同类别的变量。这样会导致这些变量的值域可能大不相同,如果使用原值域将会使得值域大的变量被赋予更多的权重。
针对这个问题,标准化可以使得不同的特征具有相同的尺度,消除特征之间的差异性。当原始数据不同维度上的特征的尺度(单位)不一致时,需要标准化步骤对数据进行预处理。
RFM_Dataset.csv 数据集笔者其实已经将尺度转化统一计分方式,为了凸显这个步骤的重要性,特别再加以说明。
R 语言中 scale 函数提供数据标准化功能,指中心化之后的数据在除以数据集的标准差,即数据集中的各项数据减去数据集的均值再除以数据集的标准差。
特别需要注意 scale 函数不接受含有字符串的数据框,使用前要进行转换。
步骤 4:
#设置随机数种子,保证可重复
set.seed(1234)
#手肘法,确定最佳聚类数目
fviz_nbclust(data_3, kmeans, method = "wss") + geom_vline(xintercept = 3, linetype = 2)为保证实验可重复进行,需设定随机数种子。
factoextra 包中包含许多用于聚类分析和可视化的函数,包括:
| 函数 | 功能 |
| dist(fviz_dist, get_dist) | 距离矩阵的计算与可视化 |
| get_clust_tendency | 评估聚类趋势 |
| fviz_nbclust(fviz_gap_stat) | 确定最佳的聚类数 |
| fviz_dend | 树状图的增强版可视化 |
| fviz_cluster | 聚类结果的可视化 |
| fviz_mclust | 基于模型的聚类结果的可视化 |
| fviz_silhouette | 聚类中的轮廓信息的可视化 |
| hcut | 分层聚类的计算并剪切树 |
| hkmeans | 分层的k均值聚类 |
| eclust | 聚类分析的可视化增强版 |
利用“手肘法”,找到最佳聚类数目。随着聚类数 K 的增大,样本划分会更加精细,每个群的聚合程度会逐渐提高,那么误差平方和 SSE 自然会逐渐变小。
即随着聚类数目增多,每一个类别中数量越来越少,距离越来越近,因此 WSS 值肯定是随着聚类数目增多而减少的,所以关注的是斜率的变化。
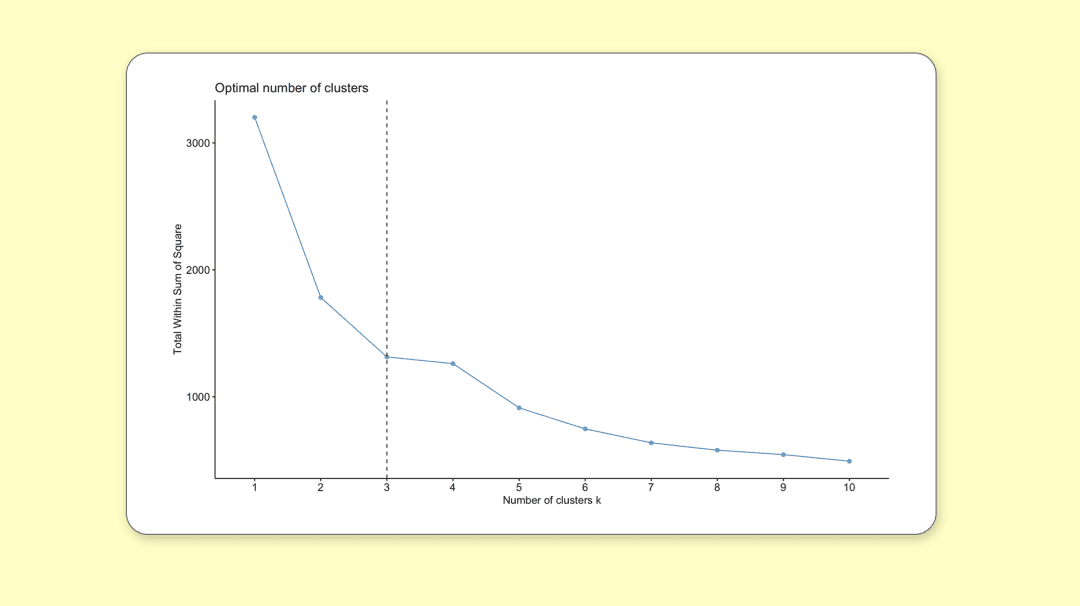
聚类数趋势图
在 WWS 随着 K 值的继续增大而减少得很缓慢时,认为进一步增大聚类数效果也并不能增强,也就是说 SSE 和 K 的关系图是一个手肘的形状,存在的这个“肘点”就是最佳聚类数目。从 1 类到 3 类下降得很快,之后下降得很慢,所以最佳聚类个数选为 3。
步骤 5:
#进行聚类
result <- kmeans(data_3,3)kmeans 函数还提供了像 iter.max(最大迭代次数)、 nstart(起始随机分区的数量)等等,有需要可以根据函数用法自行调整,这里使用的是默认的参数设定。
步骤 6:
#可视化聚类
fviz_cluster(result, data = data_3)使用 factoextra 包生成的聚类后的分布图。
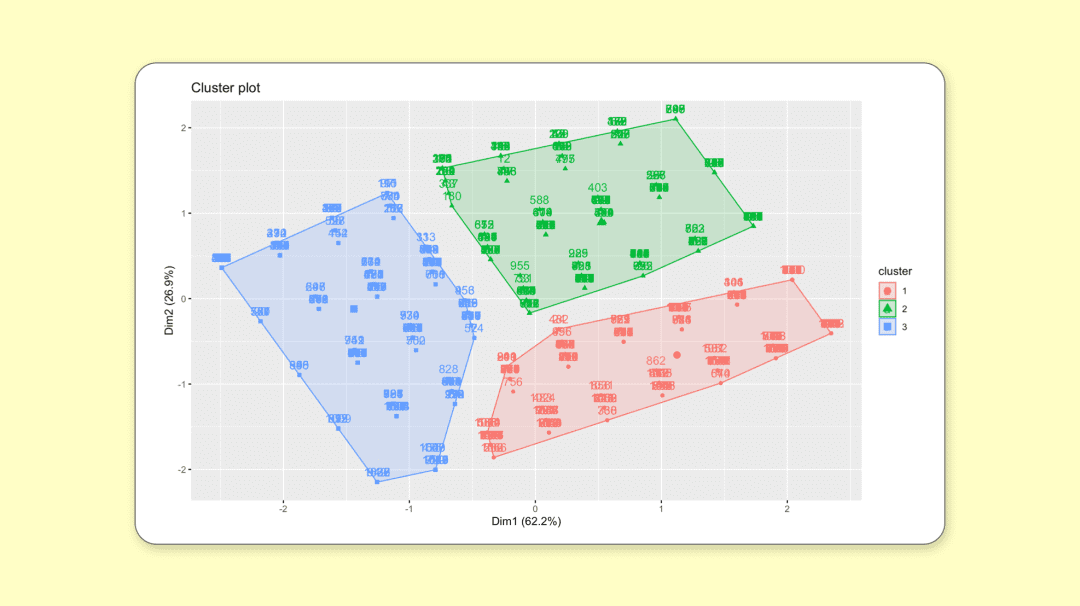
聚类划分图
步骤 7:
#聚类结果导出
result_output <- data.frame(data_1[,1:4],result$cluster)
write.csv(result_output,file="/Users/guofu.long/Desktop/result_output.csv",row.names=T,quote=F)聚类结果列表。
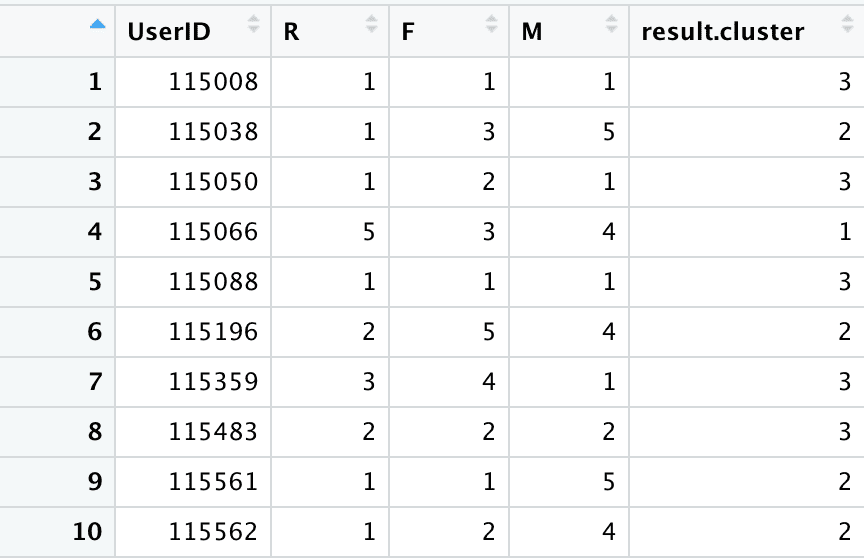
客户分群匹配列表
6、小结
最后,利用 K-Means 聚类算法和 RFM 模型得到客户分群只是开始,由于聚类(即数学上的相似性)所产生的客户分群,分群本身不能直接产生价值,无论分群用的是啥模型,最后的结果也只是一个数据标签而已。还需要结合数据本身的特点和业务特性进行意义赋予,才能够产生与之匹配的运营行动方案。
观察聚类后被分为 3 种类型的公司客户,群体表现上可以看出,3 种类别可以划分为【类别1 : 类别2 : 类别3 = 高价值 : 中价值 : 低价值】。
客户体验管理依据对应的类型采取行动方案。
本文提供的仅仅是区别于单一使用 RFM 模型进行客户分群的思路,希望对你有所启发。
本文完.
公众号:龙国富,人因工程硕士。致力于终身学习和自我提升,分享用户研究、客户体验、服务科学等领域资讯,观点和个人见解。
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/quan/69226.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫