信息随时随刻在产生,它为世界指出两条路:一条路布满着那些故步自封、因循守旧企业的「尸体」;另一条则为拥有数据思维和掌握数据驾驭能力的企业铺就康庄大道。
数据驱动增长是我们持续关注讨论的话题。神策数据创始人桑文锋,以第一人称视角,分享他如何在百度期间通过试验方式,提升「百度知道」项目核心指标的实战案例复盘,以及在百度内部搭建数据平台的阶段始末。
桑文锋,神策数据创始人兼 CEO,浙江大学计算机科学与技术专业硕士,在百度任职 8 年,从无到有构建了百度用户日志大数据平台,覆盖数据收集、传输、元数据管理、作业流调度、海量数据查询引擎及数据可视化等。
我如何将百度知道的核心指标提升 7.5%
在我刚加入百度时,「百度知道」已经成立三年,采用「问答」的形式,每天有 9 万多次提问和 25 万多次回答。由于产品形态成熟、数据稳定,所以优化与提升空间非常狭小。
为了提升百度知道的核心指标——回答量,我们开始研究用户,并尝试对不同用户采用不同的策略。比如为他们展示不同的样式和界面,以此来提升百度知道的产品黏性和价值。
在 2008 年初,我们开始尝试通过待解决问题推荐的方式来提升回答量。
第一次,基于核心用户。我们抽取了 35 万个核心用户群 —— 近 1个月回答问题的次数在 6 次之上的用户群体 —— 为该用户群体抽取了 17 万多个兴趣词,并做了个性化推荐。
这次试验前后历时 3 个多月,结果却十分令人失望。我们发现,用户只是将回答问题的入口,从之前的分类页面改到了个人中心,仅此而已,用户回答量没有发生变化。
对此,我们进行了反思。一般来说产品的优化与提升只有两种思路,要么吸引更多新用户,要么在单个用户上「榨取」更多价值。既然老用户被「榨取」得差不多了,不妨尝试拉新用户,进而扩大用户规模。
因此,我们进行了第二次尝试,基于所有用户做个性化推荐,而非仅针对核心用户。
百度内部当时有一个项目叫「后羿」,起源于百度在 2008 年做个性化广告的设想,即在用户进行搜索操作时,基于用户所搜索的关键词和用户行为记录,为用户推出相关广告。
用户通过浏览器进行访问的时候,都会种下一个 Cookie,用户在百度贴吧、百度知道、百度网页所浏览的信息都能通过 Cookie 串到一起。这为后续进行用户行为分析打下了坚实的根基。
于是,我们直接基于这些数据,根据用户的检索和访问页面的标题进行兴趣模型训练,抽取每个用户权重最高的 5 个兴趣词,当用户访问百度知道的详情页时,我们基于每个用户的兴趣词做实时搜索,将 7、8 个待解决的问题放到页面右侧。
这次尝试效果非常好,新版上线后,百度知道的回答量提升了 7.5%,而我也因此获得当时百度个人的最高荣誉 —— 「最佳百度人」奖项。
接下来,我对百度知道又做了一些改良,比如让推荐问题更具多样性、按照用户对「兴趣点」发生的时间进行权重调整等。但我也发现再往后提升就比较困难了,在这之后,我被安排到一个数据统计团队工作。
从零到一构建百度大数据分析平台
从 2008 年加入数据统计团队之后,我就开始专注在大数据分析平台。当时还没有「大数据」的概念(大数据的概念大约在 2011 年出现),我在百度从零到一做这个事情的过程可以分成三个阶段。
第一阶段:2008 年,日志统计平台
2008 年,百度流量已经很大,尤其是百度知道、百度贴吧的数据量。前面提到,百度强调要用数据说话,这点我是非常认可的。百度做产品、功能都要基于数据。但当我们需要进行流量统计和数据分析时,就遇到了问题。
因为各业务都会有处理起来非常烦琐的需求:要写脚本。这导致整个需求响应周期非常长,维护多个脚本十分麻烦,很容易出问题。当时主要基于单机来计算,数据规模稍大的任务,通常要跑好几个小时。
为解决这个问题,我们当时想到使用 Hadoop。
可以说 Hadoop 是整个大数据生态的根基,其作用就像 PC 领域的 Windows。通过它我们可以实现海量数据的存储和分布式计算。当然,我们现在所说的 Hadoop 生态,还包括了数据传输、机器学习等其他组件。
当时 Hadoop 还只是测试版,使用起来非常不稳定。我们在进行平台设计时,留有两套计算接口:一套将数据提交到 Hadoop 平台,一套将数据提交到已有的单机服务。
Hadoop 到底能不能解决我们的日志统计问题,我们心里没底。如果 Hadoop 满足不了需求,我们就还是用单机做计算。
做一个平台并不难,关键是怎么做一个好用的平台。
我把常用的统计分析需求进一步抽象,分别抽象为计数统计、去重统计和 Top N 统计,并设计了一个界面,可以通过点选直接生成对应的任务,整个操作非常流畅。下图当时我们做的日志统计平台架构图。
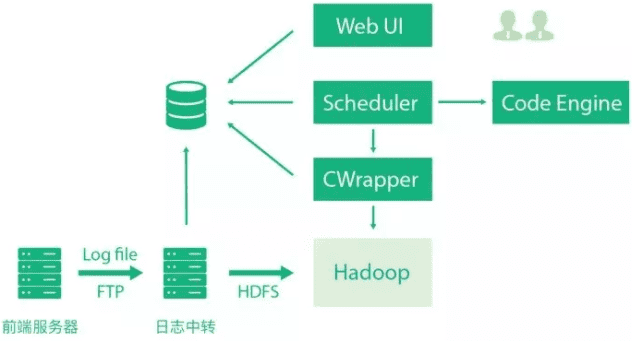
平台发布后的效果让我很震惊。首先是常规的需求开发,从几天降到了几分钟。其次是运行周期,从单机计算变成一百多台机器分布式计算,几个小时的任务变成一两分钟。
经过一年多的时间,整个公司都统一到这个平台。这是我在百度做的最有成就感的一件事。
但是,基本统计需求得到解决后,很多新需求又被释放出来。由于整个公司都在用,用于日志统计平台的机器从 100 多台增长到 5000 台,我们每个季度提预算的时候都要提 1000 台机器,我心惊胆战,毕竟日志统计团队做的这些统计任务到底有多大价值,很难衡量。
后来我的团队从以计算为中心的思路,转变为以数据为中心,也就是构建数据仓库。
第二阶段:2011 年,用户数据仓库
当时百度已经有几十条业务线,这些业务线从源头产生的数据质量不高,而且推动这些业务线进行改造实在太难了。我们就采用折中的方式:保持源头不动,将非结构化的数据结构化,使整个公司的业务线形成用户数据仓库。在这个基础上,构建不同业务的主题数据,在此之上建立 BI 支持,这就形成了一个数据金字塔,如下图所示。
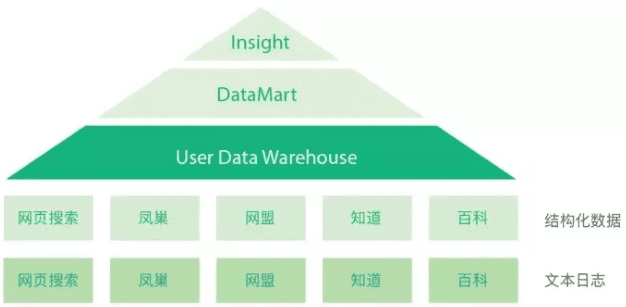
这其中最核心的就是 User Data Warehouse 部分。我们当时采用一种 Event(行为事件)模型,把用户在百度进行的任何一次行为记录,都规范为一个 Event。
Event 的属性包括用户 ID、时间、设备信息、行为特有的参数等。这样,全百度的业务线都统一到一张表上,我们通过用户 ID 把用户在百度各个业务线的访问行为全部抽出来,再这上面做数据挖掘、数据分析变得非常容易。

第三阶段:2013 年,数据源管理
当我们构建整个数据金字塔,进入新的数据阶段后,又出现新的问题。虽然整个架子搭起来了,但是四处漏风。
每次源头的变更,我们都要进行新的数据清洗和入库工作,开发周期和后续的运算周期非常长。业务线在上线之后不能马上使用数据,我们数据团队也疲于奔命。
痛定思痛,我们觉得问题的关键还是在数据源,要从源头去解决这个问题。之后我们做的事情可以分成三块:
- 第一块是从数据源方面,将我们开发的内部的结构化日志打印库和字段变更审核系统,引入和 Google Protocol Buffer 作为结构化的格式;
- 第二块是开发新的实时传输系统 Minos,将批量数据传输的方式改造为实时数据传输。
- 第三块是查询,对查询引擎本身做了改造,改造的时候提出数据从源头产生之后马上就能通过查询引擎分析的目标。
在整个数据源管理的项目中,最难的不是系统组件的开发,而是推动各个业务线配合升级新的日志打印方式。
我当时让成员做了一个 Web 版的中国地图,把省份和大城市标记为百度的核心业务线,每推动一个地方完成改造就插上红旗。经过一年半的时间,这份地图上都插满了红旗,这是我在百度做的第二有成就感的事情。
我相信,在不远的将来,不管你处在什么行业什么职位,数据分析都是你不得不具备的一种能力。为此我们还推出一本新书,名叫《数据驱动:从方法到实践》。
本书提供给你一个极好的知识储备的机会,它有三点非常值得推荐:
- 第一,浅显易懂地表达大数据的底层技术,让你能够明白数据怎么产生,怎么加工,怎么存储和运算;
- 第二,抛开了晦涩难懂的各种模型和算法,将最普适的数据洞察和分析的方法呈现给你,让你能迅速具备“阅读数据”的能力;
- 第三,清晰地将电商、互联网金融、零售、SaaS 软件等行业鲜活的数据应用案例呈现给你,让你加深对数据应用的理解。
相信大家阅读此书后会更深入的了解,数据是如何驱动企业发展与产品迭代的。
文:桑文锋 整理:范冰@增长官研究院
相关文章推荐:
《分析了近5万首《全唐诗》,发现了这些有趣的秘密》
《从 0 到 1 搭建流量转化分析体系》
《以红酒电商为例,探讨如何做到增长黑客》
更多精彩,关注:增长黑客(GrowthHK.cn)
增长黑客(Growth Hacker)是依靠技术和数据来达成各种营销目标的新型团队角色。从单线思维者时常忽略的角度和高度,梳理整合产品发展的因素,实现低成本甚至零成本带来的有效增长…
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/9638.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫