作者丨青风
编辑丨六子
“跟大模型说过最近肠胃不好,给推的晚餐竟然还有辣子鸡!”小刘的吐槽极具代表性——拥有万亿参数的AI大模型,却记不住用户的饮食习惯。
这是当前大模型广泛存在的结构性问题:AI“健忘”,尤其缺乏长期记忆。大模型可以解答博士生都难解答的数学难题,但却总忘记你的喜怒哀乐;AI Agent智能体可以做一份完美的计划任务,却又像个新手一样转眼就把前面的工作经验忘得一干二净。
AI大厂们也意识到了这个底层问题,纷纷加码研究。OpenAI的CEO奥尔特曼曾表示,GPT-6的关键就在于记忆。但行业目前仍缺乏一个系统的解决方案。

*图源记忆张量
让行业没有想到的,一家创立只有两年来自中国的初创企业——记忆张量,率先补上这个⾏业最急缺的结构性空白。该公司不仅发布了业内⾸个记忆分层的新架构⼤模型,还推出了⾏业⾸个记忆操作系统MemOS,把AI记忆从概念做成产业级底座。
也因此,记忆张量不仅获得了近亿元的天使轮融资,技术方案还被Meta、Google等大厂跟进。
AI的“健忘症”能否被破除?记忆系统又是否会重塑AI形态?
01
「AI的“金鱼记忆”困境」
在电影《土拨鼠之日》里,菲尔每次醒来都得重新认识世界。现在的大模型们也总在对话中“重置”。
比如,周一你对大模型说,“记住:我只喝加冰不加糖的拿铁。”而到了周三,你开启全新对话:“今天想喝杯咖啡,推荐什么?”大模型的回答可能是,“美式、卡布奇诺、焦糖玛奇朵都很受欢迎哦!”
没错,它就像金鱼一样,完全忘记了“不加糖拿铁”这回事!
大模型的“健忘”在日常问答中引来的可能只是吐槽,但在商业应用中引发的则可能是客户的愤怒。
有电商平台测试发现,当用户第3次咨询订单状态时,AI客服的准确率从第一次的90%骤降至31%,因为之前两次对话的内容它已经“失忆”了。一位用户愤怒地抱怨:“我连续三天和AI讨论旅行计划,今天问‘之前说的那趟攻略’,它却反问‘请问是哪次旅行?'”
AI 为什么容易失忆?这其实源于 Transformer 架构的本质特性。大模型的“记忆”就像一个容量固定的小抽屉,被称为“上下文窗口”。以GPT-4为例,它的“记忆抽屉”最多只能装下约32,768个文字,约100页书的内容,当抽屉装满时,新进来的信息就会把旧信息挤出去。即使现在业界在追捧的超长上下文,不仅让模型的成本变得更高,而且会让模型变的更加不稳定,其背后的原因还是注意力机制在长距离依赖下天然脆弱,导致了超长上下文只能充当缓存,无法成为记忆。
而更核心的是,与人类不同,大模型并没有真正的“理解”能力,它只是在统计规律上匹配,而非真正“记住”信息的含义,所以更容易丢失信息。

*图源互联网
行业其实很早便意识到了这个问题,ChatGPT、谷歌Gemini、Anthropic旗下Claude、马斯克的xAI等大模型也都曾宣布上线记忆功能,支持多轮对话。
有业内技术专家介绍,当前行业主流的AI记忆策略有两类:⼀类是⻓上下⽂,把历史对话原样塞进prompt(提示词)⾥;另⼀类是RAG(检索增强生成),⽤向量检索拉回相关知识再拼进输⼊。
但这两种⽅式都还有很大的局限性。“它们只能提供⼀次性的、表层的‘记住’,本质上还是短时记忆,不具备真正的累积和演化能⼒。”记忆张量CEO熊飞宇对青澄财经表示,“这些方案最⼤的不⾜是,⼤都不是给Agent⽤的。现在的⼤多数Agent仍然属于短线智能——每次任务都从零开始,没有任务级状态,没有统⼀的记忆时间线,也⽆法跨场景迁移经验。这也是为什么它们做单轮任务很强,⼀旦任务跨度变⻓、逻辑链条变复杂,就明显乏⼒。”

*图源记忆张量发布会 记忆张量CEO熊飞宇
从上面可以看出,⼤⼚这两年也在做AI记忆,但多半停留在“功能级”。而熊飞宇认为,过去行业在解决“信息能不能回忆”,但还没有解决“记忆能不能影响智能行为”。这就意味着,AI记忆的缺位,不是功能而是系统层次的断裂。
现在,这个空缺的行业板块被记忆张量这家初创企业填上了。
02
「像操作系统⼀样管理AI记忆」
“⼈类之所以能发展,是因为我们能记住、能总结、能更新,⽽这三点恰恰是当下AI Agent的能⼒缺⼝。”记忆张量CEO熊飞宇对青澄财经表示,“AI的下⼀次进化,⼀定从拥有记忆开始。”
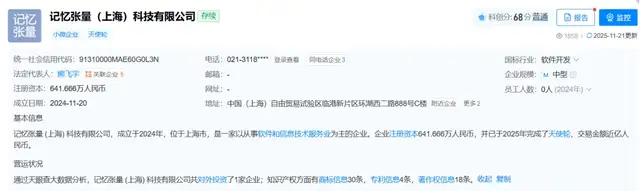
*图源天眼查
据天眼查显示,记忆张量成立于2024年,但其团队在2023年中便开始组建和孵化,当时聚在⼀起想做⼀件真正具备⻓期价值、⽽不是短期热点的事情。他们在⼤量⼀线实践⾥看到⼀个⾮常现实的问题:⼤模型的“瞬时聪明”和企业的“⻓期需求”之间⻓期存在断层。
他们判断“记忆”是⼀个可以真正做成系统级基础设施的⽅向,⽽绝不只是单点功能。这个对行业的预判很快就有了成果。2024年7⽉,在世界⼈⼯智能⼤会(WAIC)上,记忆张量发布了业内⾸个记忆分层的新架构⼤模型;同样,在2025年的WAIC上,又发布了⾏业⾸个记忆操作系统MemOS。
像操作系统⼀样管理AI记忆,⽽不是靠上下⽂堆砌、规则拼接来维持所谓的“记住”。这是行业此前从未尝试的路径。
MemOS的技术原理可以理解为三层协同:模型底座具备记忆原⽣能⼒,类似⼈脑把⻓期记忆压缩进⽪层结构;系统负责调度和编排,管理记忆的全⽣命周期;应⽤侧将所有记忆能⼒做成标准化算⼦,开发者可以像调⽤API⼀样使⽤记忆抽取、压缩、回溯、迁移等功能,⽆需理解底层机制,就能构建具备⻓期偏好、稳定⼈设和跨任务状态的智能体。
值得一提的是,记忆张量非常重视“机制公开”与“可解释”,MemOS并不是用“规则记忆”,而是将记忆写入、调度,其生命周期变成可审计、可复现、可替换的系统模块。
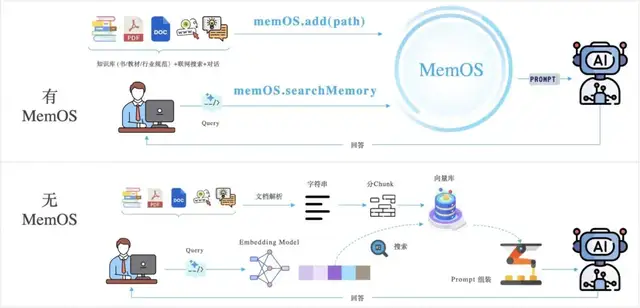
*图源记忆张量
这条路径实际效果如何?下面这个“陷阱”任务可以直观地展示。对几个主流记忆方案进行对比评测,⽤户明确要求避开所有⾼碳⽔⻝物,再让AI推荐以碳⽔闻名的意⼤利菜时,只有MemOS能够严格遵守⽤户的⽣酮饮⻝偏好,其他⽅案均出现了不同程度的“遗忘”,推荐了⽤户明令禁⽌的高碳水⻝物。
而在更专业的四⼤类权威Benchmark评测中,评测内容覆盖从“事实记忆”“偏好理解”到系统性能的全场景,将MemOS与当前市⾯上主流的开源及商业化记忆⽅案进⾏对⽐,MemOS在所有四项核⼼算法基准上稳居第一,同时在关键指标上显著降低了Token开销,可谓“既准且省”。
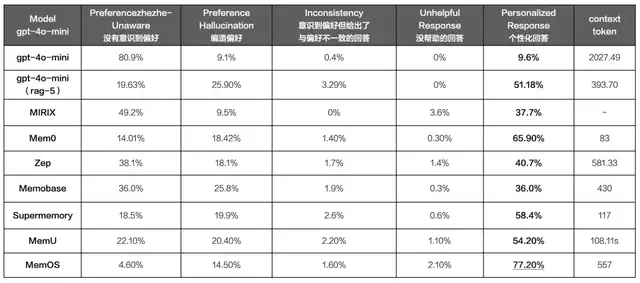
*图源记忆张量 PrefEval (0 轮无干扰)评测结果
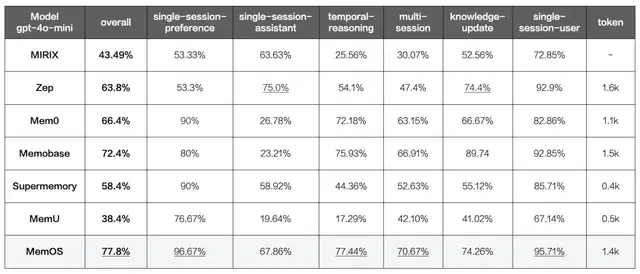
*图源记忆张量 LongMemEval评测结果
可以说,记忆张量交付出了—个可信赖的、⼯业级的记忆解决⽅案。
而记忆张量的探索,对整个行业都有极大的开创意义。MemOS解决了三个⻓期困扰⾏业的难题:AI不稳定,记不住⼈、不记⼯作、不记任务;Agent做不深,只能demo,⽆法持续运⾏;企业智能化做不下去,因为知识、经验、上下⽂⽆法沉淀。
03
「AI记忆的基础设施」
“我希望记忆张量能成为AI记忆基础设施的定义者。就像数据库改变了信息系统的形态,操作系统改变了计算机的形态,我相信记忆系统会重新定义下⼀代智能体的形态。”熊飞宇表示。
将记忆定位为AI新的基础设施,MemOS的适用范围一下就打开了:既可以是C端的大模型应用,也可以是企业级Agent。简单总结——凡是需要连续性、需要⻓期累积和需要稳定表现的场景,MemOS都有发挥空间。
熊飞宇介绍了几个典型场景:一是陪伴类、⻆⾊类、⼈格类AI;二是企业级AI助⼿,尤其⾦融、⼯业、运营商等复杂业务;三是⾏业知识沉淀型任务,⽐如客服系统、⻛控助⼿、运营分析Agent等。
事实上,记忆张量的技术方案已获得招商证券、中国银行、中国电信等头部国央企的广泛认可,累计签约金额已达数千万元。
*图源记忆张量官网
其实际落地的个性化AI⾦融投顾客服案例,带来的效果就很明显。接⼊MemOS后,系统能⾃动记住⽤户的⻛险偏好、过往问题、账户习惯、资产结构等⻓期信息。同⼀个⽤户反复来咨询,系统能保持⼀致的策略和⼈设,重复沟通减少超过60%。
另一个案例,个性化⻆⾊扮演类AI游戏更获得了玩家们的热烈反馈。集成MemOS后,游戏中的AI⻆⾊可以记住玩家的⾏为⻛格、道德倾向、互动历史,甚⾄会形成⾃⼰的偏好和性格轨迹。玩家们觉得NPC不再只是个固定化程序,而更像“活着的⻆⾊”,由此带动了游戏的⽤户黏性提升显著。
面向C端,11月27日,记忆张量又发布了一个跨平台的AI统⼀记忆管理助⼿MemOS-MindDock,支持ChatGPT、Gemini、DeepSeek、通义千问等多平台,可⾃动获取历史对话、个⼈设置与记忆内容,用户即使切换平台也能始终被“理解”。
用个形象的比喻,MemOS-MindDock就像一个专属的外置⼤脑,将信息统⼀存储,随时调⽤,让用户的个⼈记忆库持续成⻓,并始终掌握在⾃⼰⼿中。
记忆张量创业之初就保持了开放的态度,希望“记忆”能像数据库、向量库⼀样,成为AGI时代的基础能⼒,因此围绕MemOS搭建了⼀个“开源社区+云服务+⼯具链+⽣态合作伙伴”四位⼀体的体系。
目前,MemOS已全面开源,登陆魔搭社区MCP广场,还上线了扣子(coze)插件商店。此外,记忆张量还与阿⾥云、天翼云、ModelScope等⽣态伙伴形成深度合作,共同提供托管服务、模型加速、⾏业模板等能⼒,使企业可以在云端、私有化、本地端等不同部署环境下使⽤统⼀的记忆框架。
面向未来,记忆张量计划把记忆从语⾔智能,扩展到更多维度,包括多模态记忆、具身智能的动作与环境记忆,以及端侧可部署的本地记忆体,让AI在视觉、语⾳、⾏为和真实世界的交互中都具备持续性的时间线和经验积累。
“我们的⽬标⾮常清晰:让每⼀个AI都拥有⾃⼰的‘过去’和‘成⻓轨迹’,让智能体第⼀次具备可持续的⽣命线。”熊飞宇表示。
- END -
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/model/148341.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫