

伴随着PP-OCRv5的持续破圈,一个AI大模型底层基建的新形态正在出现,它们不再是之前的模型替代式更新,即通过不同参数的调配和专有数据集的训练进行不断打榜,而是以足够工程化、足够算法架构创新式的设计,直接面向大模型文本训练底层的不完美拼图,帮助其摆脱固有的性能藩篱和生产力限制,进而拔高AI落地的上限。
小尺寸、高性能的PP-OCRv5恰是这样一个新形态的AI基建。
作者|皮爷
出品|产业家
你对OCR的认识还停留在哪里?
1966年,IBM发表了一篇长度约为1000字的文章,这篇文章中的文字和其它文章不同,采用的是特殊印刷体汉字识别技术,通过模板匹配的方法识别出文字,并进行最终排版。这就是OCR技术的第一次应用。
从19世纪60年代到如今,人们对OCR的最主要印象恰是如此,即文字识别。这种能力被广泛应用到一系列工作和产业场景,帮助人们把静态的生产资料转化为可交互、可编辑的数字资料。
但如今,这个“信息转化”的技术又迎来新的变化。
就在上周过去的9月10日,一篇名为PP-OCRv5技术博客文章登顶 Hugging Face 博客热度榜第一,这个模型技术以仅为0.07B 的极致轻量化模型体积做到整体识别精度达到SOTA水平。在多项 OCR 场景测试中,PP-OCRv5 的表现甚至超越GPT-4o、Qwen2.5-VL-72B等通用视觉大模型。
这个登顶不难理解。千分之一的参数量、足够SOTA的效果、轻量级部署……这几个反差足够吸引广大开发者成为源源不断的“自来水”。 据了解,截至目前,这个由百度飞桨团队发布的技术Blog已经连续一周霸榜 Hugging Face博客热度。
此外,在9月18日,在PP-OCRv5的热度加持下,PaddleOCR项目也更登上了GitHub全球总榜 trending榜。
实际上,OCR的重要性在今年已经成为一个共识。即在各个基座模型厂商和AI服务商的模型产品中,OCR能力往往都被嵌入进新的模型服务中,以标配技术的形式为企业提供服务。
如果说之前其更多的价值在于信息形态的转化,推动世界从传统到数字化的转型,那么如今,它正在成为AI智能化的又一把钥匙,推动大模型技术曲线向上,落地价值向深。
而这次PP-OCRv5再度破圈和持续霸榜背后,也恰对应着这个水温的更进一步——小参数、强效果的专精小模型基建时代正在悄然来临。
一、OCR,正在成为AI战场的新明珠
“现在基于多模态识别可以帮助企业构建更好的RAG能力,让模型在企业内部落地效果更好。”一位云厂商Agent平台相关负责人告诉产业家,“在大部分企业内部,图像等多模态数据才是主要数据形态。”
这番对话发生在刚刚过去的8月。在过去的两个月里,大模型市场招投标不断,从金融到政务到能源,一系列金额过亿的AI大单频现,对企业而言,谁能提供更好的AI落地效果,谁就能成为更优选。
RAG能力恰是其中尤为重要的一环。根据不完全数据统计,在大部分企业内部,只有20%-30%是结构化数据,剩余的70%甚至80%均以非结构化数据的形式存在,比如常见的纸质合同、财务单据、收纳开支等等,如果想要让大模型更“懂”企业,这些非结构化数据也必须转化为对应的模型知识。
OCR能力恰是其中的关键手段。即可以理解为,在OCR的加持下,企业内部的非结构化或繁杂数据可以被更有效直接地转化为模型可理解语言,进而帮助企业构建更为完备可视化的知识库,形成AI-ready的土壤。
“OCR识别能力有强有弱,甚至某种程度说,服务商提供的模型OCR技术能力的强弱很大程度上决定了企业在AI上落地的效果。”上述负责人表示。
毫不客气的说,如果说新能源汽车是中国工业制造的明珠,那么就今年而言,说OCR是AI大模型战场上的明珠。
与这种定位相对应的是整个OCR市场的快速扩容。一组来自Allied Market Research报告的数据显示,2024 年全球 OCR 市场规模达122.1 亿美元,预计到 2034 年将飙升至506.1 亿美元,年复合增长率(CAGR)超过15%。
从更大的视角来看,OCR的爆火早在意料之中。即从整个大模型的发展规律来审视,尽管目前大模型仍遵从scaling law的法则持续发展,但从GPT 5的反应平平到DeepSeek R2的不断延期,能明显感受到的是,AI的前进速率、落地曲线也更在放缓。
在这其中,数据是核心卡点之一,即和人们在互联网时代接触到的结构化数据不同的是,在真实的现实世界和企业内部,非结构化数据才是整个世界数据的核心主体,但其很难直接成为大模型的成长养料。
这也恰是OCR技术的“专项领域”。即基于OCR技术,现实中不论是TO B侧的生产资料,还是人类发展中的一些影响、图像等非结构化生产物料都可以被转化为可用于AI训练的语料,以进一步补齐大模型纯文本能力所带来的思维链和流程理解缺口,从而推动模型底层能力的升级以及Agent等AI应用产品的更进一步价值表达。
但把OCR和AI结合并不是一件容易的事。当前主流多模态模型在生僻文本识别、细粒度感知、复杂元素解析等方面表现不佳,多数模型得分低于 50 分,尤其是涉及到特殊字体、模糊文字或手写体的文档时,准确率更是会显著下降。
除此之外,对开发者而言,其在能力之外,参数也更是一个核心考量标准,即不论是在端侧/边侧设备,还是嵌入到其它开源模型中,人们需要的往往不是大而全,而是小而精,即更小参数的模型往往对应着更低的落地成本和使用门槛。
这个兼备技术和工程能力的OCR模型答案是否存在?
二、PP-OCRv5霸榜背后:
再度破圈的PaddleOCR
答案是肯定的。这也是PP-OCRv5这次破圈的本质原因。
首先,PP-OCRv5兼备模型的轻量级和顶尖性能,从参数量来看,其仅有0.07B 参数,约等于 Qwen2.5-VL-72B 的千分之一,同时相较于开源社群的MiniCPM-o、OCRFlux-3B等参数量级更小一个维度。
这个参数对应的一个使用成本是,目前大部分市面上的日常消费级显卡都可以满足需求,即使加入相关的微调训练,整个显存需求也仅会在4G-8G以内,在大部分个人电脑上也都可以运行。
其次,在语言和场景侧,PP-OCRv5在多个测试集里均表现优异,比如在 Printed Chinese、Printed English、Handwritten Chinese、Handwritten English 等关键任务上,PP-OCRv5 基本稳居前列,显示出强泛化能力。
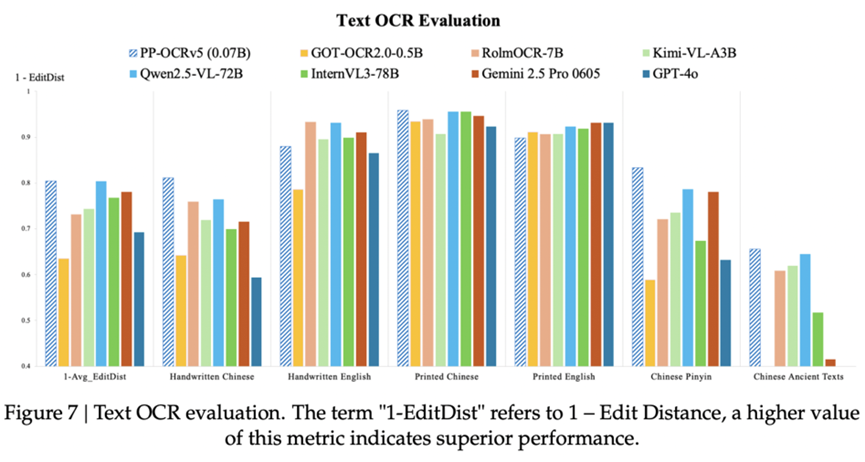
一个官方给出的更具体的成绩是,集合文心大模型4.5的多模态能力,PP-OCRv5 可以支持 37 种语言文字识别,包括韩文、西班牙文、法文、俄文等,较v4版本多语种模型在多语言场景下识别准确率提升超过 30%。
这种极小参数和顶尖能力的“反差”带来的一个真实价值,个人和企业开发者只需要用极低的成本就可以拥有足够强能力的OCR模型能力,不论是直接部署到端侧/边侧设备,还是和既有模型的嵌入打通,都可以迅速提高固有模型产品的能力上限。
产品不基础,带来的“自来水”流量自然也更不基础。
过去的一段时间里,和霸榜成绩接连出现的是一系列针对PP-OCRv5 的海内外“自来水”评价,比如Gizchina.com锐评“百度的PP-OCRv5表明,小型号仍然可以发光”,比如再比如来自一系列网友的称赞,如“データ入力、爆速化の救世主降臨✨”(“数据录入,极限提速的救世主降临✨”)、“圧倒的性能でAIモデル「PaddleOCRv5」が、たった70MBの超軽量ながら、驚異的な高精度OCR技術を実装します” (AI模型「PaddleOCRv5」以压倒性的性能,在仅70MB的超轻量体积下,实现了惊人的高精度OCR技术)等等屡见不鲜。

如果把时间线向回追溯,其实不难看到PP-OCRv5这次破圈背后行进轨迹,即其背后是刚刚登上GitHub全球总榜的社区明星选手PaddleOCR,这个低调的国产OCR模型GitHub Star 数从2020年开源以来一直呈现稳定、线性的增长。
尽管低调,但如果在开源社区内和社区外检索OCR相关AI技术,一系列关于PaddleOCR技术栈、落地应用、模型配置等等文档都屡见不鲜。
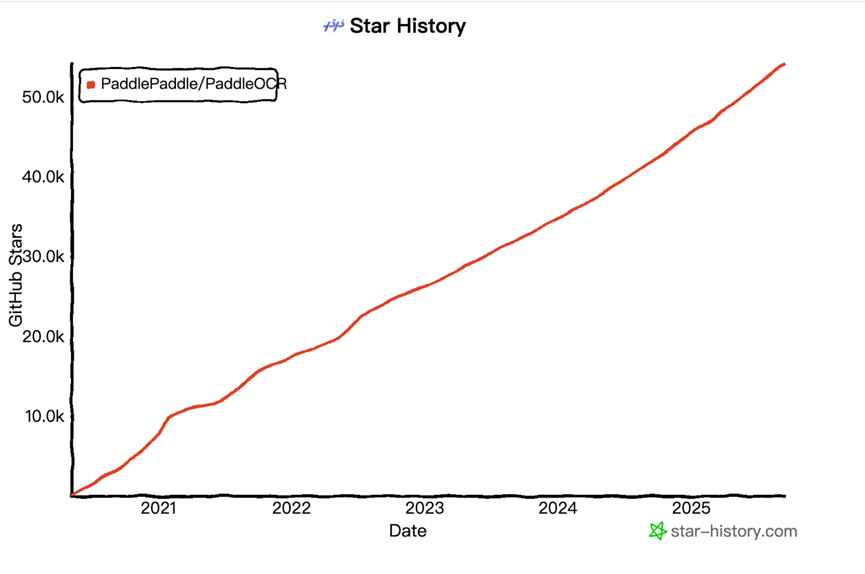
这种从2020年开源以来的稳定增长也更构成着这个国产OCR选手的特殊性,即PaddleOCR是如今全球唯一闯入头部阵营的中国 OCR 项目,其也更是GitHub 社区中唯一一个 Star数超过50k的中国OCR项目。
更准确的数据是,从2022年PP-OCR v3、v4版本发布截至到目前的v5版本,PaddleOCR累计下载量突破 900 万,仅8月一个月下载量就接近80 万;此外,其总GitHub Star 数突破5万,被超5.9k开源项目直接使用,其中包括一系列知名开源项目,如Umi-OCR、OmniParser、MinerU、RAGFlow等等。
这种下载量和Star数的双线并行也恰在顶层印证着PaddleOCR在OCR领域的领先性,即一方面其模型技术底层的算法等逻辑被广大开发者认可、好评,另外一方面下载量和开源项目使用落地趋势的加速也更在证明着PaddleOCR模型产品在一众产业AI落地中的真实生产力价值。
三、AI大模型,
进入“专精基建”下半场
自2020年推出以来,PaddleOCR一路迭代,如今已经更新至3.2版本。下载量和Star双线增长的更底层,PP-OCR等模型技术也更在不断成熟,推动着OCR在AI时代更完善基建的成型。
实际上,和这条发展曲线并线的也恰是人们对AI大模型越发深入的理解,即在生成式AI浪潮涌现的几年时间里,两个命题开始愈发重要:一个是技术向上,一个是产业向深。
而在这两个命题中,更优质的OCR能力恰都在成为核心驱动引擎。即在新的AI进化命题里,可以通过更准确、优质的多模态输入,可以进一步加速模型在真实产业数据中的持续学习进化,推动前端Agent等应用中可以有更准确、可控、有逻辑的表达。
这也正是PaddleOCR的行进路线。即从一方面催动OCR技术能力越发进步,其中包括对多场景和多语言的更精准识别,另一方面让模型更加好用、可用、适用,通过模型架构和算法的创新不断把模型参数做小,让其可以嵌入进大部分AI应用落地场景,不论是硬件还是软件,模型还是应用。
同样值得一提的是,在融合PP-OCRv5的PaddleOCR 3.2版本中,一系列工程能力也更在被持续迭代,比如在之前3.1版本的MCP接入方式之外,3.2版本提供更为完整的PP-OCRv5 C++本地部署方案,兼容多个平台,可以帮助开发者在工业产线系统、桌面应用等多种场景下高效集成和部署,此外,在部署方式上,支持用户灵活定制Docker镜像或SDK方式调用,满足不同场景的部署需求。
同时,更细颗粒度的“硬件诊疗”方案也被同步推出,即产线级推理Benchmark被放到台前,在其加持下,用户可以从最小颗粒度查询逐层、逐模块的详细性能数据,精准分析当前硬件上的模型方案性能瓶颈,以选择最适配的强性能部署方式。
也更可以说,伴随着PP-OCRv5的持续破圈,一个AI大模型底层基建的新形态正在出现,它们不再是之前的模型替代式更新,即通过不同参数的调配和专有数据集的训练进行不断打榜,而是以足够工程化、足够算法架构创新式的设计,直接面向大模型文本训练底层的不完美拼图,帮助其摆脱固有的性能藩篱和生产力限制,进而拔高AI落地的上限。
小尺寸、高性能的PP-OCRv5恰是这样一个新形态的AI基建。
AI大模型的发展绝对不只是互联网上的一众结构化数据的成果,更多的人类文明、产业实践、工业智慧都在一个个文档书本、表格数据、单据流程中,这些如今伴随着PP-OCRv5等更强OCR“眼睛”的加持,为AI大模型向AGI的持续进阶之路提供着更优质的成长养料。
AI大模型终究会驶向AGI,这是一个毋庸置疑的终局,PP-OCR等更多AI专精模型的出现,恰在加速推动AI潮流持续向前。
本文来自投稿,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/coo/143751.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






