
大家好
去年1月20日,DeepSeek推出开源的R1推理模型,以至于整个春节期间它都以华人之光的身份在各个地方被讨论着。不得不说,AI在国内C端用户的第一次现象级破圈,属于去年的DeepSeek时刻。
前不久还和朋友打赌,今年过年,他们一定也会憋个大的,大张旗鼓地复刻去年的荣耀。
好家伙,就在前天,DeepSeek团队默默地扔出了一个重磅炸弹:DeepSeek-OCR2,距离“春节档”整整早了大半个月。

这篇文章在科技圈以外,被讨论的还不是很多。文章讨论的主要是OCR(Optical Character Recognition,光学字符识别,指模型从图像中识别、提取并理解文字的能力)。有些同学看到这个可能会纳闷,“这都2026年了,不就是把图片转成文字吗?扫描全能王几年前不就行了吗?这也值得发篇论文?”https://wxa.wxs.qq.com/tmpl/pb/base_tmpl.html
如果你把这次更新仅仅看作是“识别率提高了一点点”,那你就低估了 DeepSeek 的野心。
在视觉语言模型VLM被广泛,大量使用的今天,DeepSeek又重新回到视觉的源点提出了一个简单却又直接的灵魂拷问:AI看图片的方式是正确的么?人类又是怎么看图片的?
DeepSeek 用这个模型告诉我们:过去的 AI 都在死记硬背,从今天起,机器终于学会了“带脑子”阅读。
1.你的眼睛,真的在“扫描”吗?
讲技术之前,先做一个有趣的自我观察。
当你打开电商App想要购物,或者在电脑上打开一份复杂的季度财报时,你的眼睛是怎么工作的?
你会像一台复印机一样,从左上角的第一个像素开始,匀速向右移动,扫完一行再扫下一行,直到右下角的页码吗?
当然不会。如果你这么看屏幕,大概率会被认为是机器人。
很多消费品牌会采用“眼动仪”技术,来追踪消费者在逛商场或者在看手机屏幕的时候,视线是怎么“阅读”的。

品牌们拿到消费者视线的热力图后,会根据热力图进行陈列,把最希望被你看到的元素,放在你最容易看到的“热区”。
人的目光永远是跳跃的、有策略的、基于语义逻辑的。你看哪里,取决于你想知道什么,以及你刚才看到了什么。
但是,过去的 AI 并没有这双“慧眼”。
传统的视觉模型(VLM)处理图像的方式,不管图片里是蒙娜丽莎还是Excel,它都强制性地从左到右、从上到下,把二维的图片拍平成一维的序列。
这就导致了一个让无数开发者崩溃的后果:
处理多栏排版的学术论文或报纸时,AI 经常“傻傻分不清楚”,直接把左边栏的最后一行,拼接到右边栏的第一行。字都认识,连在一起全是乱码。
这就好比你让一个完全不懂排版规则的实习生去整理文档,他把所有字都打出来了,但顺序全是乱的。
2.DeepSeek 的解法:给 AI 装上“逻辑光标”
DeepSeek-OCR2 最大的突破,就是它重构了 AI 看图的方式。
他们设计了一个全新的核心组件——DeepEncoder V2 。这个编码器做了一件极具“人性”的事:它引入了“视觉因果流”。
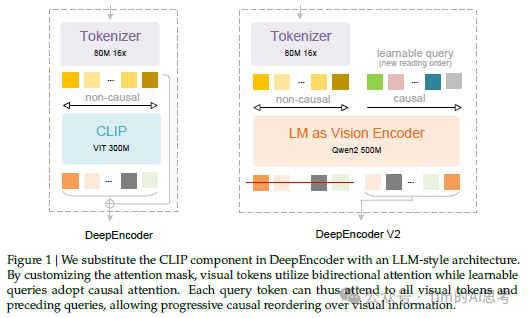
简单来说,DeepSeek 给 AI 装上了一个“逻辑光标”。
当一张复杂的图片喂进去,模型不再是无脑扫描,而是先进行推理:
第一步:看懂布局(Where to look)。 模型里的“因果查询Token”会先对画面进行全局感知,分析出哪里是标题、哪里是表格、哪里是正文,规划出一条合理的阅读路径 。
第二步:提取内容(What to read)。 按照规划好的逻辑顺序,精准地抓取信息。
在这个过程中,DeepSeek 甚至做了一个极其大胆的架构创新:他们去掉了传统的视觉编码器CLIP,直接用一个 500M 参数的小型语言模型(Qwen2-500M) 来充当“眼睛” 。
这意味着,这只“眼睛”本身就是有脑子的!它天生就懂语言逻辑,所以在看图的时候,它是带着理解去看的,而不是单纯地记录像素。
结果就是: 哪怕是排版最变态的杂志、嵌套了三层逻辑的表格、或者是写满数学公式的草稿纸,DeepSeek-OCR2 都能像人类专家一样,把它们清晰还原。
3.“一图压千词”:降维打击的效率哲学
说实话这是我觉得最牛逼地方。
C端的用户可能没有感知,但是B端的企业主和开发者们一定为昂贵的token成本愁大了脑袋。
DeepSeek-OCR2 带来的不仅是准确率,更是成本的指数级下降。
这就涉及到了一个反直觉的信息论概念。
以前,为了让大模型看懂一张复杂的图表,传统的方案会生成海量的描述性代码(Token)。一张高密度的A4文档,可能需要消耗 6000 甚至 7000 个 Token 才能描述清楚 。
在 AI 的世界里,Token 就是钱,Token 就是时间。
而 DeepSeek-OCR2 玩了一手“极简主义”。
得益于它那双懂逻辑的“眼睛”,它学会了“抓重点”和“遗忘细节”。它知道背景里的噪点不重要,知道表格的框线不需要逐一描述,它只提取核心的语义结构。
结果是惊人的:同样复杂的文档,DeepSeek-OCR2 只需要 256 到 1120 个 Token 就能完美表述
这意味着什么?
- 效率提升了 6 倍以上。
- 成本降低了 80% 以上。
这就好比以前你请人做会议纪要,对方按字收费,给你发来 1 万字的流水账;现在 DeepSeek 这个金牌助理,给你发来 1000 字的精炼要点,而且逻辑更清晰。
不得不感慨,在极致成本这块,还得是中国团队牛逼
4.迈向“原生多模态”的终局
读懂这篇论文,你甚至会触摸到 DeepSeek 的下一个野心。
在论文的讨论部分,作者提到了一个词:"Native Multimodality"(原生多模态) 。
现在的 AI(包括之前的 V3),本质上还是“盲人”。你上传图片,它其实是先用外挂工具把图片转成文字,再用脑子思考。
但 DeepSeek-OCR2 的探索(用语言模型直接做视觉编码器)暗示了未来的方向:
未来的 DeepSeek,可能不再需要“翻译”这个步骤。
它将拥有一个统一的“大脑”,这个大脑既能读文字,也能直接看图像,甚至听声音。它将不再是把世界翻译成文本,而是直接“理解”世界的原始信号。
结语:AI 真的越来越像“人”了
DeepSeek-OCR2 的发布,我相信又会是给整个行业不小的启发。
技术的进步,有时候不在于把模型做大,而在于把逻辑做深。
当我们奋力前行越做越大的时候,不妨回到上游,从一些最基础的环节再对自己进行灵魂拷问,可能多问一个为什么,就会对后面的范式有翻天覆地的影响。https://wxa.wxs.qq.com/tmpl/pb/base_tmpl.html
当然再展望一下VLM,对于我们每一个职场人来说,这意味着那个曾经“经常看走眼”、“乱码频出”的笨拙 AI 助手,终于毕业了。它现在准备好,帮你去啃那些最难啃的硬骨头了。
这次,它是真的“看懂”了。
源:Tim
本文经授权发布,不代表增长黑客立场,如若转载,请注明出处:https://www.growthhk.cn/cgo/geo/153035.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫